-
Type:
Bug
-
Resolution: Works as Designed
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: 3.11.2, 3.12.4, 4.0.3
-
Component/s: API
-
None
-
Environment:mongodb 3.6.2 has been used, others not checked
-
None
-
None
-
None
-
None
-
None
-
None
-
None
The background:
In our system we have two GridFS buckets:

I realised that the second one it getting slower and slower as long are we are using it (putting in more/bigger files). Also the delete operation was/is terribly slow on some nodes, up to 20 seconds per file.
When searching for the problem I also checked the indices, because in most of the cases wrong/missing indices are the reason for slow DB results. And I found this:
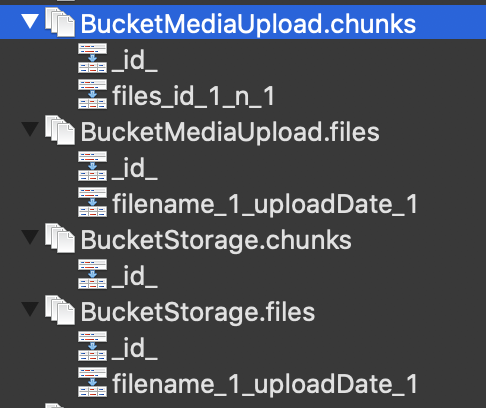
While one of the buckets has the indices expected by the GridFS specification, the other does not. And this is the case on several and independent, but not all of our server instances that run the same software, but do not share the same data.
The problem:
I analysed the source code of the java driver in the version I use (3.11) and the newer ones (3.12, 4.*, master) and found out that the indices are only created under the following conditions:
(GridFS.java)
public GridFS(final DB db, final String bucket) { ....... // ensure standard indexes as long as collections are small try { if (filesCollection.count() < 1000) { filesCollection.createIndex(new BasicDBObject("filename", 1).append("uploadDate", 1)); } if (chunksCollection.count() < 1000) { chunksCollection.createIndex(new BasicDBObject("files_id", 1).append("n", 1), new BasicDBObject("unique", true)); } } catch (MongoException e) { //TODO: Logging }
This means: When I create a GridFS object which holds less than 1000 items, these indices should have been created, but that's not the case as you can see on the screenshots.
Currently I don't know why for one DB they are created and not for the other, but my speculation is that it is has to do with the fact that on some instances especially the one bucket which is missing the index is filled up with many files directly after creation. So it could be the case, that...
1) the index is not created, because the bucket does not exist at startup
2) the index is not created on the second connect, because the db already contains more than 1000 chunks.
==> the index is never created
I will try to further investigate and provide updates. But I think this is quite an important issues, because it really drastically affects performance.