-
Type:
Improvement
-
Resolution: Fixed
-
Priority:
 Unknown
Unknown
-
Affects Version/s: None
-
Component/s: None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
The C extensions have handling for encoding dict, RawBSONDocument, and any mapping class. We can optimize these code paths for the common case which is standard dict.
For example, write_dict here https://github.com/mongodb/mongo-python-driver/blob/7e96249/bson/_cbsonmodule.c#L1510 checks for "_type_marker" and PyObject_IsInstance() on every mapping object even if we know that object is a dict already.
We should skip those checks if the object is PyDict_Check or PyDict_CheckExact. We might be able to apply this style of optimization in other parts of the encoding/decoding logic too.
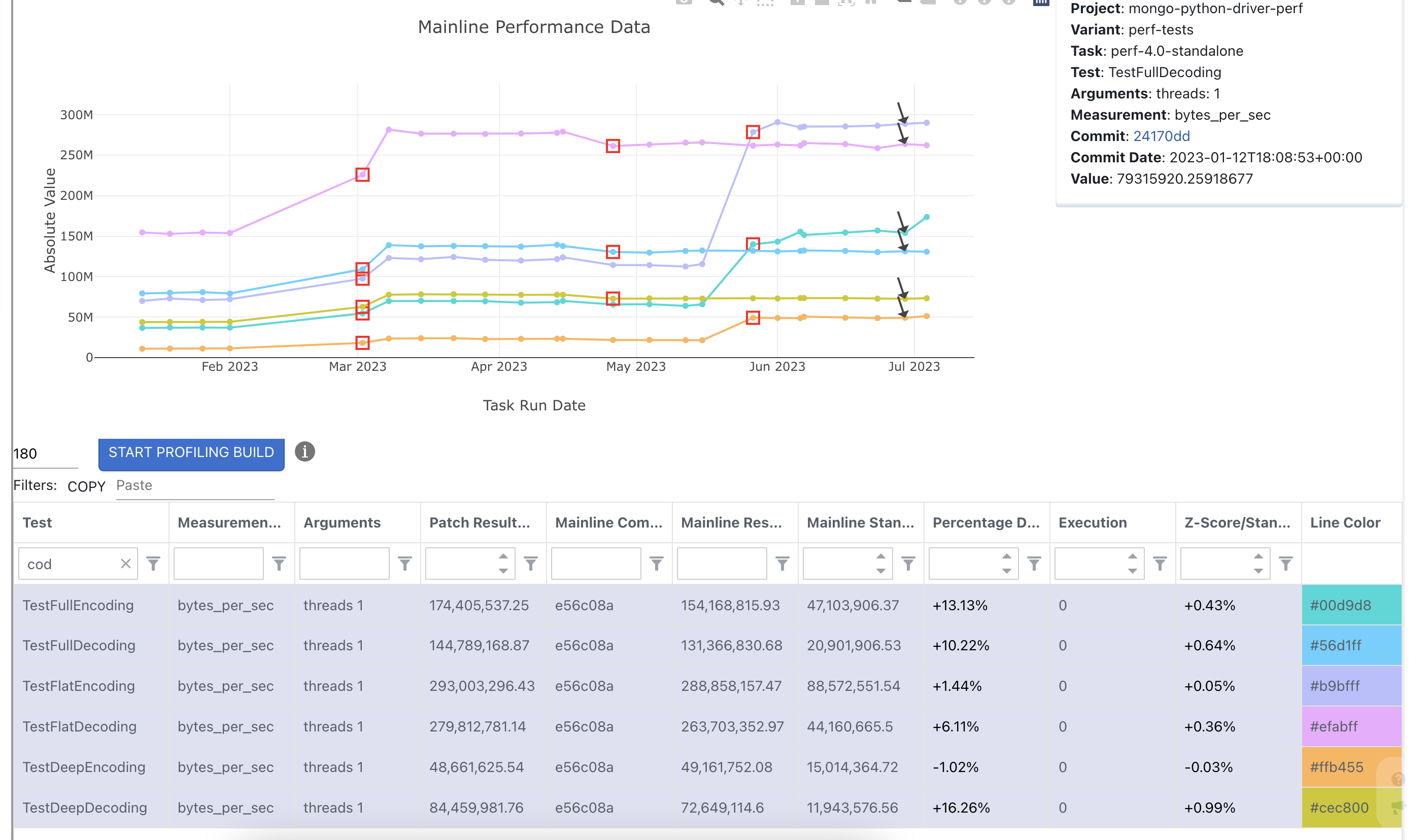
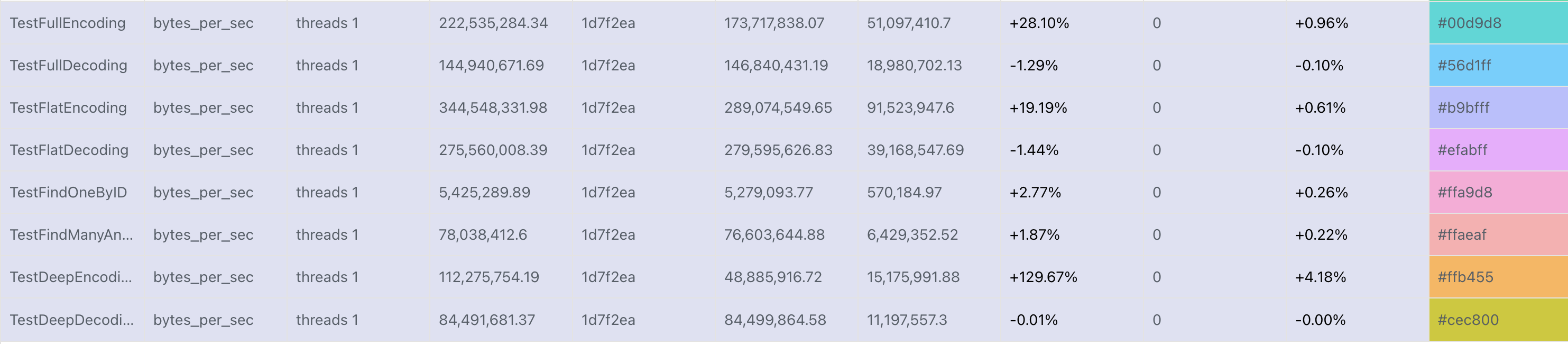
These inefficiencies could explain why encoding a deeply nested document is much slower than decoding the same deeply nested document. We should expect encoding to always be faster than decoding since the encoding side should allocate fewer Python objects. Notice that TestDeepEncoding has lower throughput than TestDeepDecoding:
{kind=link}
{kind=link}
- is related to
-
-
- Closed
-