-
Type:
Improvement
-
Resolution: Won't Fix
-
Priority:
 Major - P3
Major - P3
-
Affects Version/s: 1.8.3
-
Component/s: None
-
Environment:ruby2.0.0p0, rubygems v2.0.2
-
None
-
None
-
None
-
None
-
None
-
None
-
None
A performance testing is run by inserting about 6000 words into a collection with the format like
{"word":"example"}. Each of this will be inserted into a document.
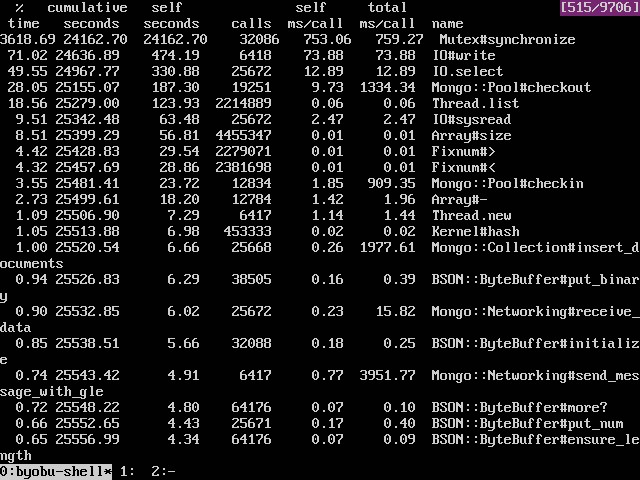
When the test is running with pool size 50, and total inserting threads are 40, the performance is very bad. From the profiling report, we could see the top contributors are Mongo::Pool#checkout and Mutex#synchronize, which use more much time for every call and total self-seconds.
% cumulative self self total
time seconds seconds calls ms/call ms/call name
618.69 24162.70 24162.70 32086 753.06 759.27 Mutex#synchronize
71.02 24636.89 474.19 6418 73.88 73.88 IO#write
49.55 24967.77 330.88 25672 12.89 12.89 IO.select
28.05 25155.07 187.30 19251 9.73 1334.34 Mongo::Pool#checkout
In my enclosed testing code, you could see there are no shared variables to update so I don't need to call synchronize. so I think it is the synchronization done in the pool.
Is that possible to improve the performance by using less shared things and use more Thread.current[:local] variables to reduce the numbers of the synch?
I'm not sure what could be done to improve the performance of checkout, but I feel there is much some ways to improve it.