-
Type:
Bug
-
Resolution: Done
-
Priority:
 Major - P3
Major - P3
-
Affects Version/s: 2.5.4
-
Component/s: Concurrency, Querying
-
Environment:Linux ip-10-237-131-70 3.11.0-12-generic #19-Ubuntu SMP Wed Oct 9 16:20:46 UTC 2013 x86_64 x86_64 x86_64 GNU/Linux
-
ALL
-
None
-
3
-
None
-
None
-
None
-
None
-
None
-
None
Queries of the type
find({x: Integer, y:Integer})
on documents which schema is
{x: Integer, y: Integer}
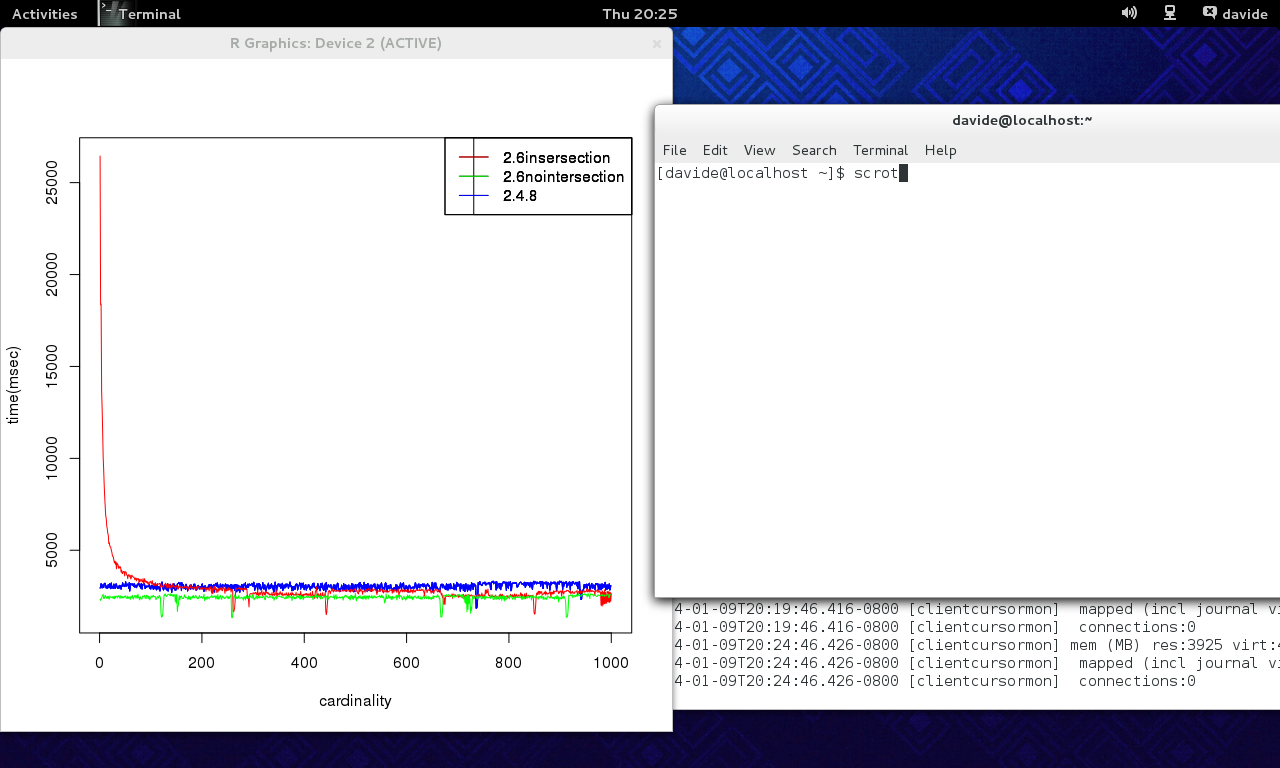
are about 2x slower on 2.6 with respect to 2.4, in case one of the two field key set has low cardinality, index intersection is on, and two indexes are built (one on each field, x and y).
Disabling index intersection makes the problem going away.
Analysis of the problem:
It mostly relies on the couple idx intersection + low cardinality. Imagine the worst case scenario where you have all the documents where one field is fixed and the other is an increasing integer, namely:
{x: 0, y: 0}, {x:1, y: 0}, {x: 2, y:0} ...
and the two aforementioned indexes.
Now, if index intersection is ON, and you do a query of the type
db.goo.find({x: something, y: 0})
your query engine will likely scan the whole index for y (and part of the index for x), causing the huge performance drawback. This is somewhat confirmed by experimental results, see attached screenshot + script. There's a point after which index intersection is a clear win – unfortunately I think it's hard to choose such value without statistics/histograms.
Now, I still think that this is somewhat a corner case because people should never build an index on a key with very low cardinality as the one showed in the example, but still, 2.4.8 doesn't exhibits the following behavior so the query optimizer should probably do its best to not pick the idx isect plan in this case.