-
Type:
Bug
-
Resolution: Incomplete
-
Priority:
 Critical - P2
Critical - P2
-
None
-
Affects Version/s: 2.6.3, 2.6.4
-
Component/s: Index Maintenance
-
None
-
Environment:Amazon Linux AMI release 2014.03
r3.2xlarge instances
-
Linux
-
None
-
0
-
None
-
None
-
None
-
None
-
None
-
None
We have a 3 shard cluster, which each shard consisting of a primary, secondary, and a hidden secondary (for EBS snapshots). Each of the nodes is identical to all of the others.
We've seen the issue described below once every 2-3 weeks on 2.6.3. After upgrading to 2.6.4, we saw it at least hourly, sometimes as frequent as every 5-10 minutes. When it does occur, our production system goes down.
The symptoms of the issue are a sudden spike in the number of connections to the visible secondary on our first shard. We haven't seen it occur on the primary, nor have we seen it occur on any of the other shards.
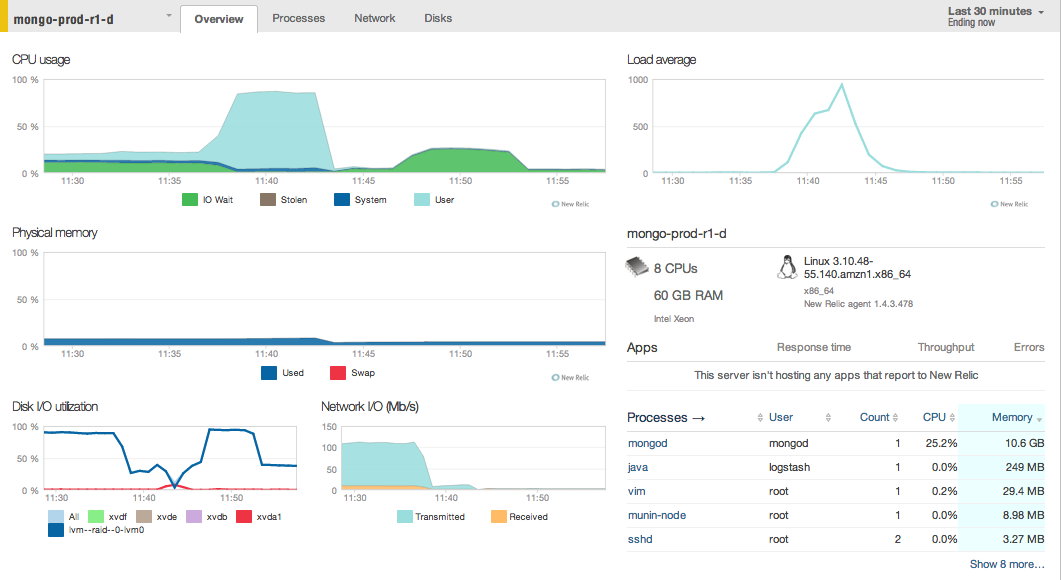
The connections seem to all deadlock-- the I/O on the machine drops dramatically when this occurs. I've attached a screenshot of the machine reporting from New Relic that shows this-- user CPU spiking while disk IO goes to 0. I've also attached the mms reports for this, which show the connections spiking while the number of operations fall dramatically.
Interestingly the lock spikes during this time as well, and that is all coming from the local database.
There is no much in the logs of interest, and certainly no smoking gun. I've attached the log, and the spike in connections appears to occur at: 2014-08-22T18:38:10.730+0000
Finally, restarting the effective mongod immediately resolves the issue.

- is related to
-
-

- Closed
-