-
Type:
Bug
-
Resolution: Done
-
Priority:
 Major - P3
Major - P3
-
Affects Version/s: 2.8.0-rc0
-
Component/s: Performance, Storage
-
ALL
-
-
None
-
3
-
None
-
None
-
None
-
None
-
None
-
None
This may be "works as designed" (i.e. that WT is going to be slower for traversing large data structures in memory) but I would like to make sure and quantify the expected behavior here if that is the case.
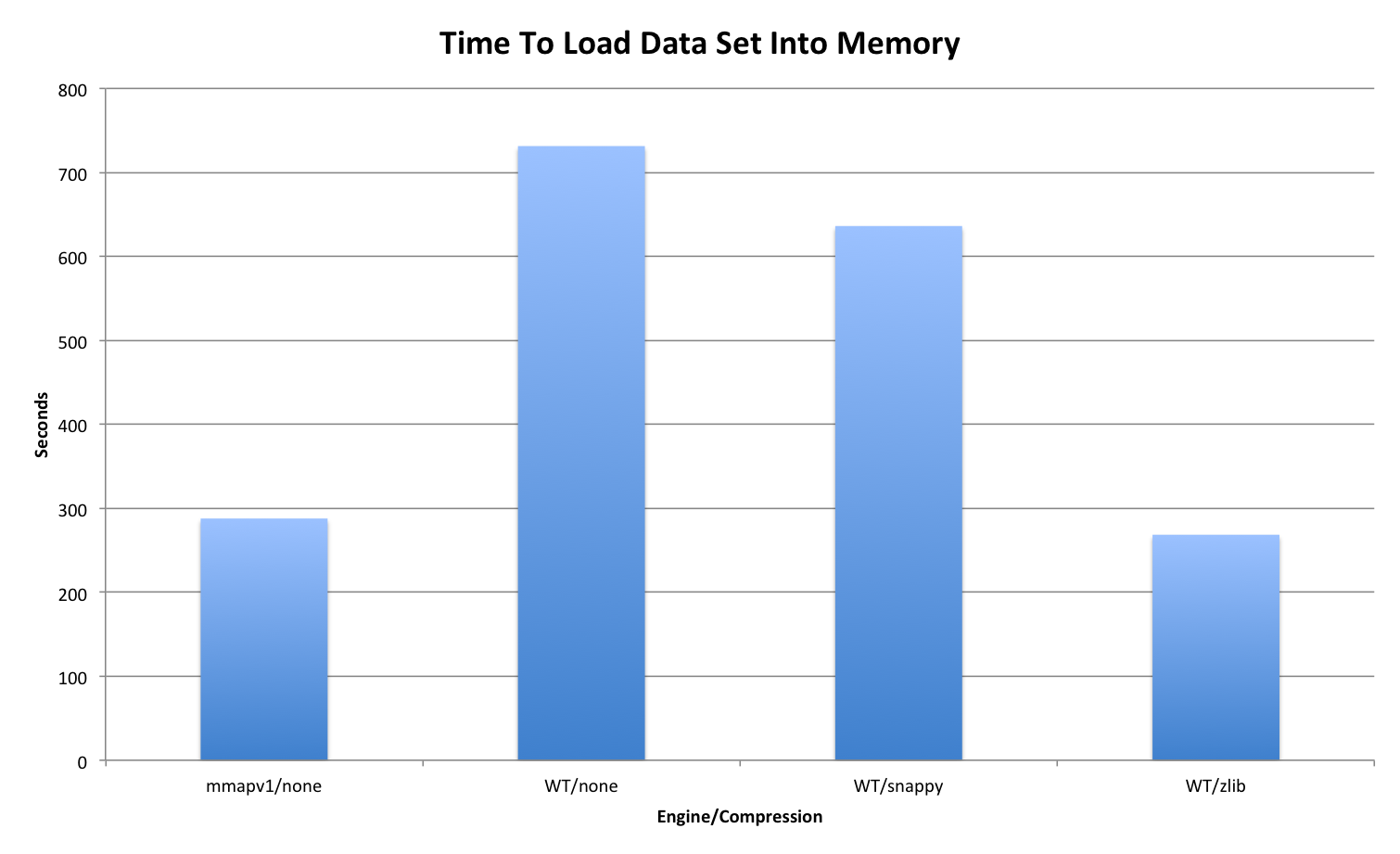
While attempting to profile the benefits of compression in terms of bandwidth savings, the expected performance of the default snappy compression (which delivered decent on-disk compression) looked slower than expected, significantly slower than mmapv1.
That led to a round of testing to better understand what was going on here. So, I used 4 basic storage engine configurations:
- mmapv1
- WT with no compression ("block_compressor=")
- WT with snappy (default, so no block_compressor specified)
- WT with zlib ("block_compressor=zlib")
The only WT config that came close to the mmapv1 performance was zlib, and that was on the read from disk test. So, I decided to test on SSD rather than spinning media, the result was that everything got a bit faster, but the relative differences remained - WT was still significantly slower.
For my initial testing methodology, since I was trying to demonstrate the benefits of compression for IO bandwidth savings, I had been clearing the caches on the system after each run.
Now that IO appeared to have no effect I decided to do consecutive runs of the collection scan, which would make the second run all in-memory (the collection is <16GiB and the test machine has 32GiB RAM, even with indexes it would fit in memory, but indexes are not in play)
However the collection scan was still slow with WiredTiger even when the data was already loaded into RAM. The mmapv1 test dropped from the ~300 second range down to 13 seconds, but the WT testing showed no similar reduction - it did improve, but was still in the hundreds of seconds range rather than double digits.
I have tried tweaking cache_size, lsm, directio, readahead to no effect (the last two before I had ruled out IO issues completely), but no significant improvement either.
Basic initial graph attached, I will add detailed timing information, graphs, perf output below to avoid bloating the description too much.
- is duplicated by
-
SERVER-16164 optimize table scans on wiredtiger
-
- Closed
-
- related to
-
-
- Closed
-