-
Type:
Bug
-
Resolution: Duplicate
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: 2.8.0-rc2
-
Component/s: Performance
-
None
-
Fully Compatible
-
None
-
None
-
None
-
None
-
None
-
None
-
None
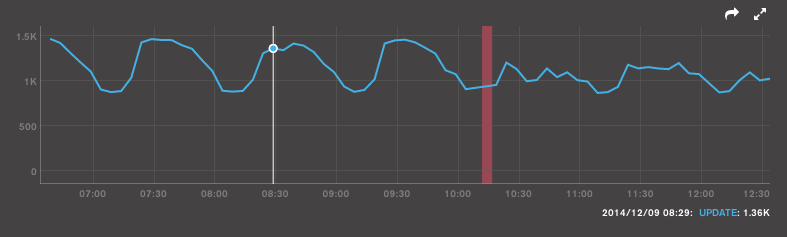
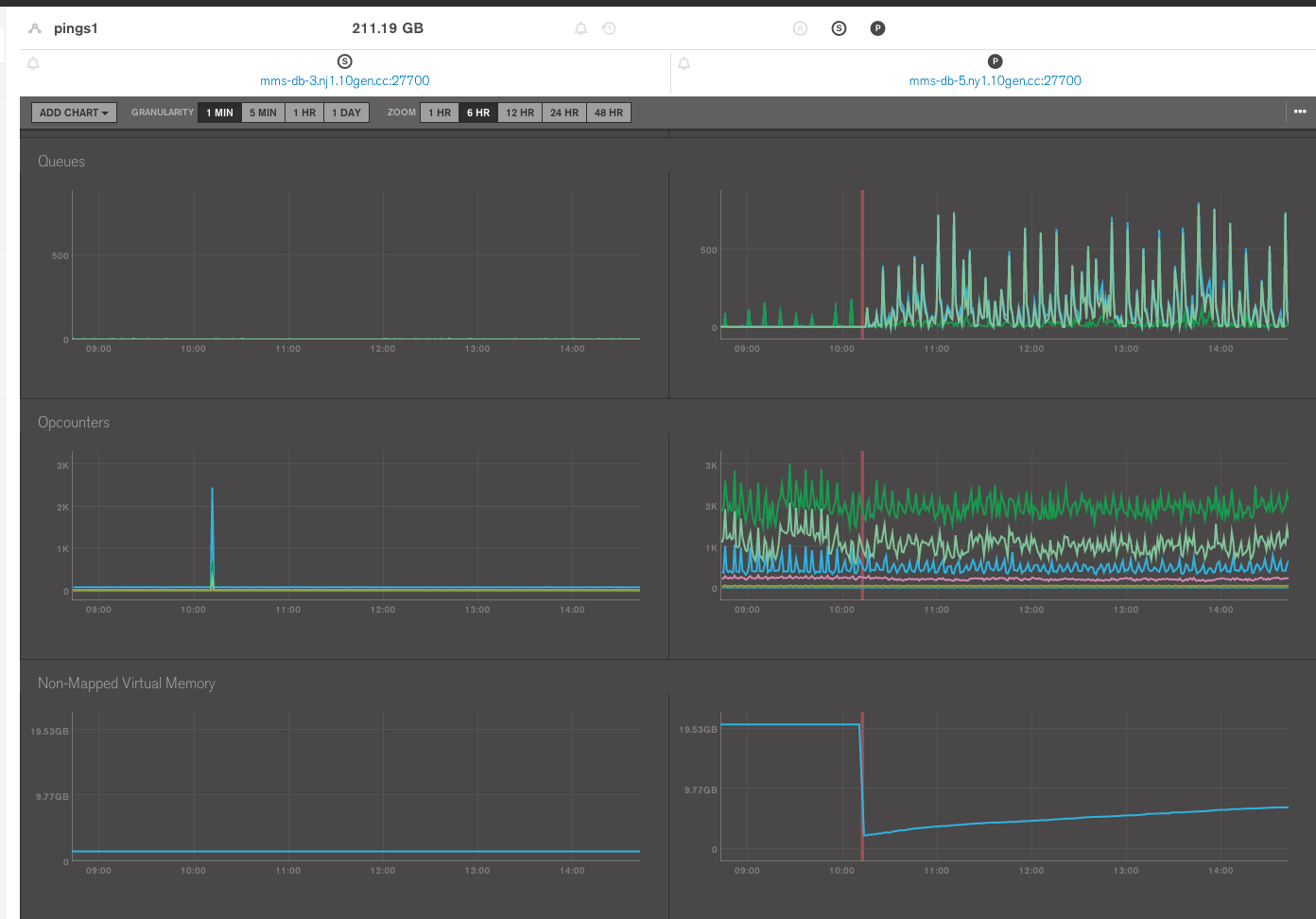
Please see attached MMS graph showing a time range that shows a particular workload on 2.6.3 and then 2.8.0rc2 (mmapv1). Note that the query opcounters (bright green, highest line) and the update opcounters (lighter green, lower line) both decreased when we upgrade to 2.8.0rc2.
One significant workload on this replica set has the following hourly pattern:
- 0-20: "rest"
- 20-40: do as much work as possible. Lots of updates and reads.
- 0: bail, even if not done

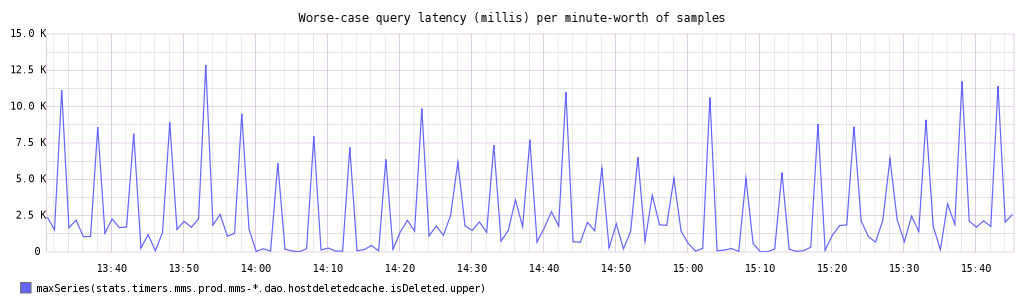
You can see the change a bit more clearly in this 5 minute average of just update opcounters:


- duplicates
-
-
- Closed
-