-
Type:
Bug
-
Resolution: Duplicate
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: 2.8.0-rc4
-
Component/s: Sharding
-
None
-
Fully Compatible
-
ALL
-
-
None
-
3
-
None
-
None
-
None
-
None
-
None
-
None
On 2.8.0-rc4, both mmapv1 and wiredTiger, I've observed a peculiar biasing of chunks toward to a seemingly random 1 or 2 shards out of the 10 total for new sharded collections.
The workload of the application is single-threaded and roughly as follows:
1.) programmatically creates a sharded database and a sharded collection
2.) creates the {_id:"hashed"} index and a {_id:1} index.
3.) inserts ~220k documents, each about ~2kB in size, with a string _id.
4.) repeats from step #1, flipping back and forth between two databases, but always on a new sharded collection. Meaning when the workload completes, there's two sharded databases, each with 24 sharded collections on {_id:"hashed"}, each collection containing ~220k documents.
Initially my the workload application starts out distributing chunks across all shards evenly as expected for each new sharded collection. However at some indeterminate point, when a new collection is created and sharded, it's as though 1 or 2 shards suddenly become "sinks" for a skewed majority (~80%) of all inserts. The other shards do receive some of the writes/chunks for the collection, but most are biased toward these 1 or 2 "select" shards.
After the workload completes, the balancer does eventually redistribute all chunks evenly.
I've had difficulty reproducing with a simpler setup, so I'm attaching some logs for the wiredTiger run where exactly 1 shard ("old_8") was the biased shard:
- mongos.log.2015-01-03T21-22-44 - single mongos the workload was talking to
- mongodb.primary-recipient.log.2015-01-03T21-22-31 - the primary of the suddenly "hot" biased shard "old_8"
- mongodb.first-configsvr.log.2015-01-03T21-22-34 - first config server in the list of 3.
Timing of logs:
- on Jan 3rd about 18:06 UTC the run beings
- on Jan 3rd about 19:55 UTC the shard old_8 primary "JM-c3x-wt-12.rrd-be.54a0a5b5e4b068b9df8d7b9c.mongodbdns.com:27001" begins receiving the lion's share of writes. (opcounter screenshot from MMS attached, as well as MMS chunks chart for an example biased collection.)
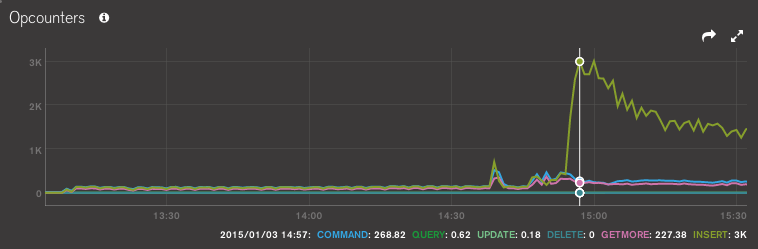
- in general, it seems like collections after "benchmarks2015010500" from both databases are when the issue starts. E.g., "benchmark2015010500", "benchmark2015010501", "benchmark2015010502", etc
Environment:
- EC2 east, Ubuntu 14.04 c3.xlarge
- All nodes on same VPC subnet
- 2.8.0-rc4, 1GB oplog, journaling enabled
- Logs attached are for wiredTiger, but have observed on both engines.

- depends on
-
SERVER-9287 Decision to split chunk should happen on shard mongod, not on mongos
-
- Closed
-
- duplicates
-
-
- Closed
-
- is related to
-
-

- Closed
-