-
Type:
Bug
-
Resolution: Won't Fix
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: None
-
Component/s: MMAPv1
-
None
-
Storage Execution
-
ALL
-
None
-
3
-
None
-
None
-
None
-
None
-
None
-
None
Overview
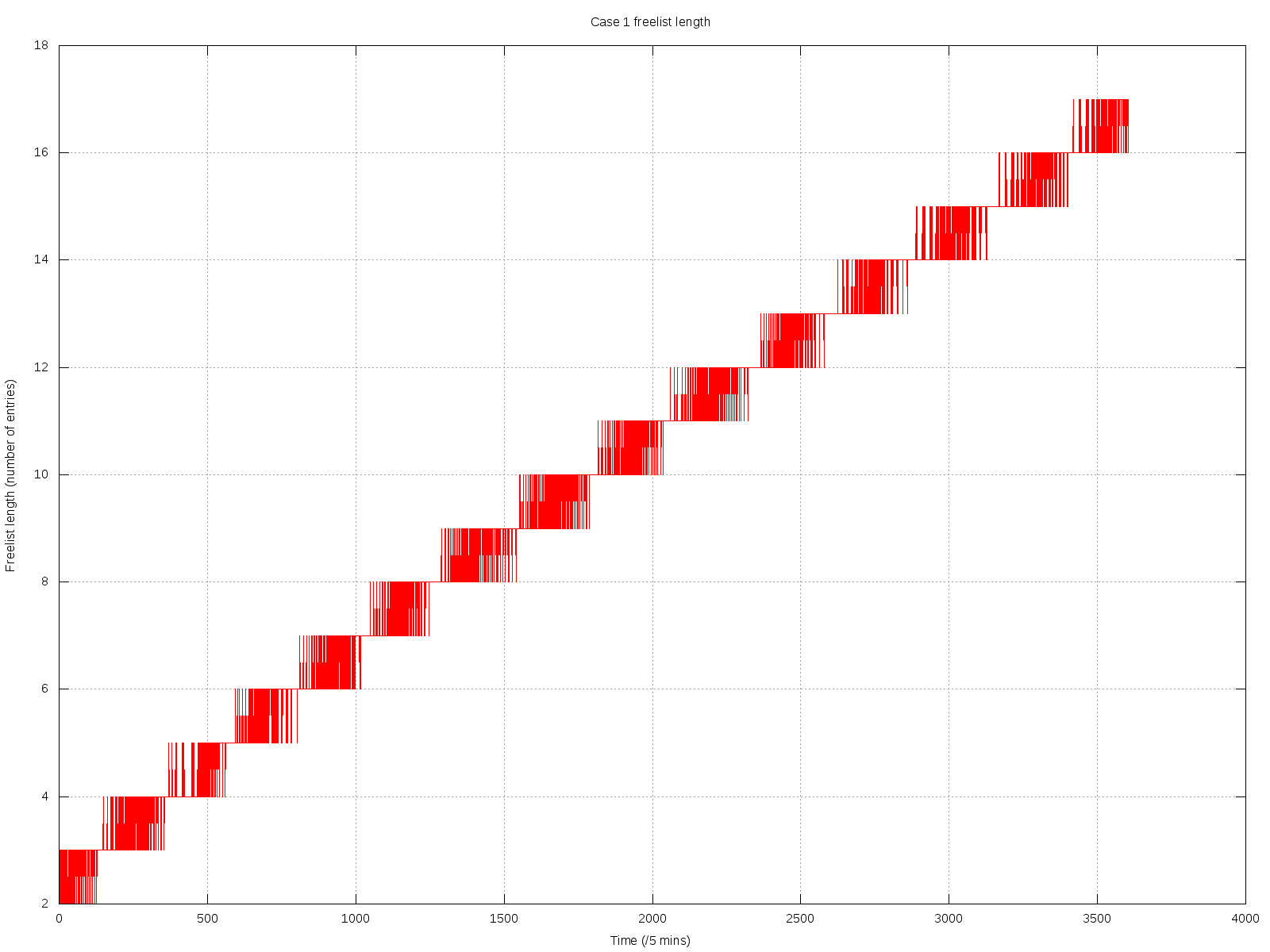
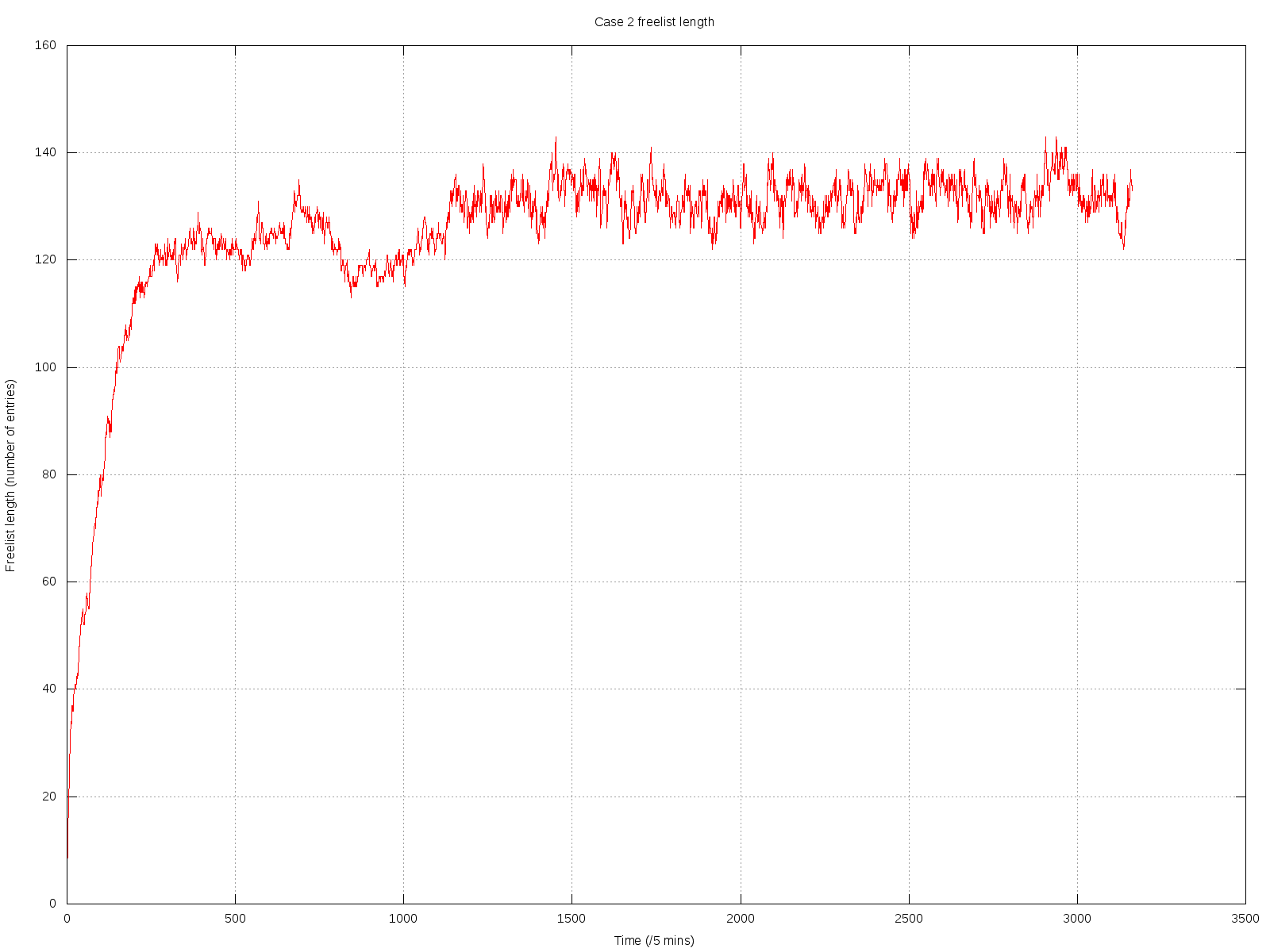
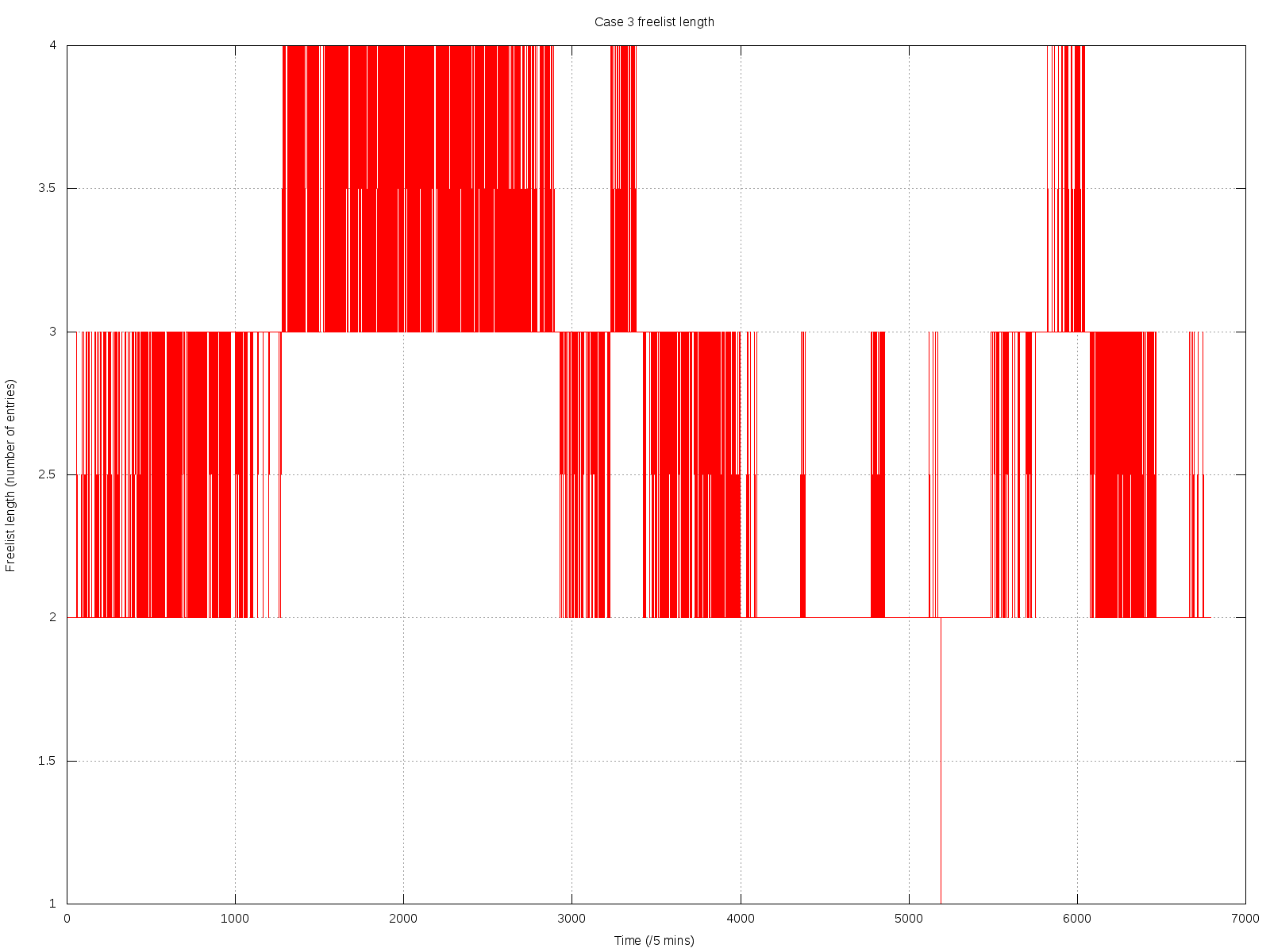
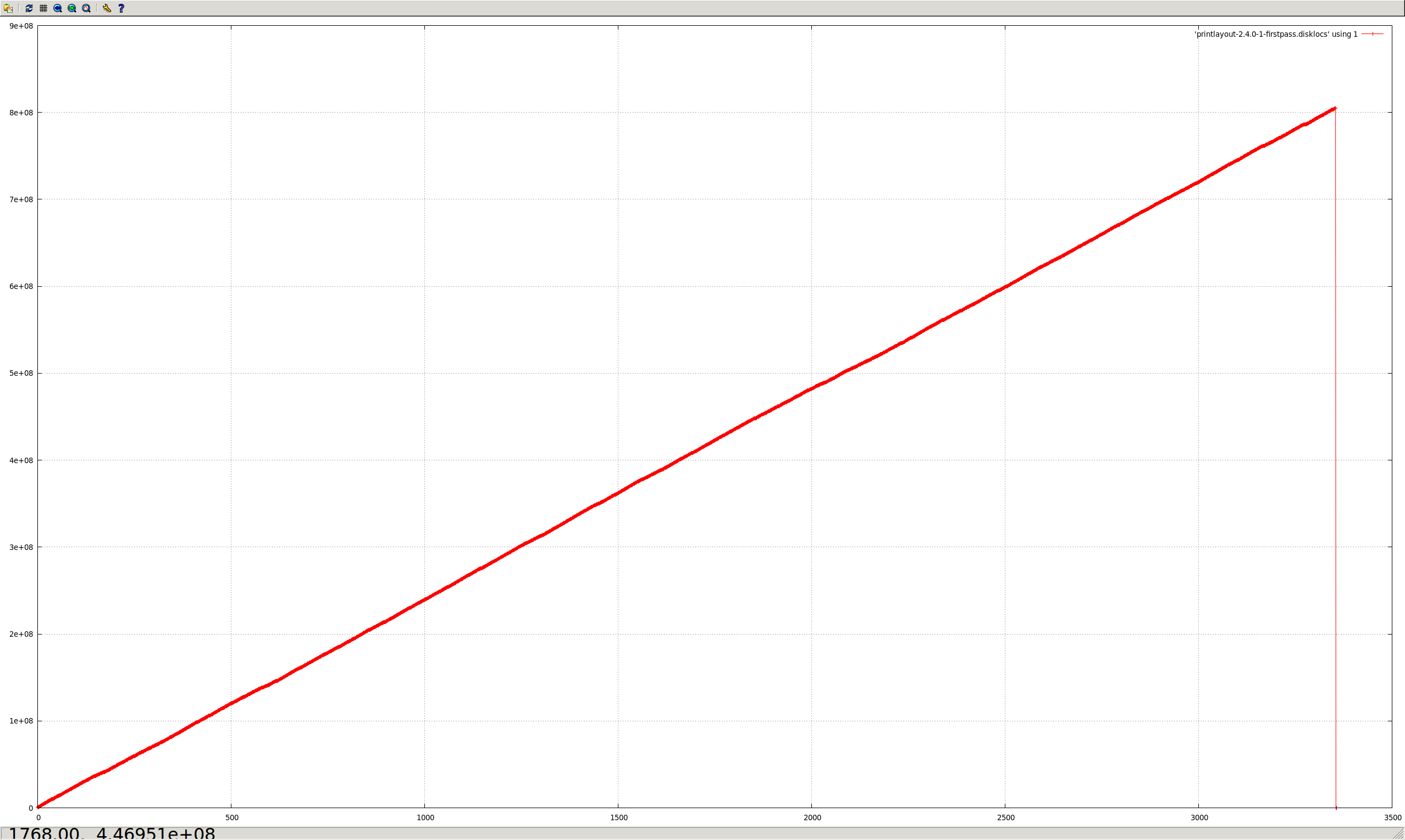
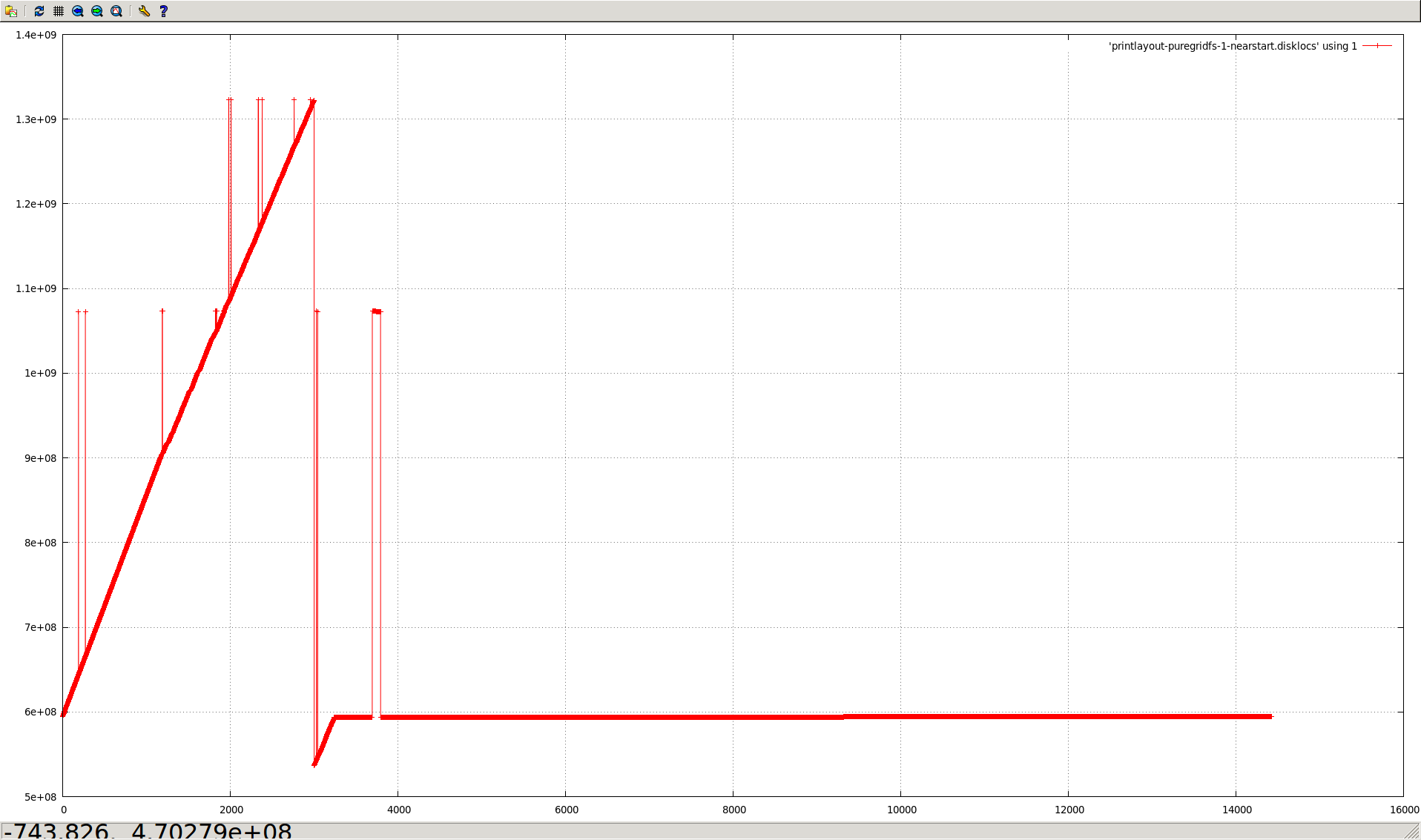
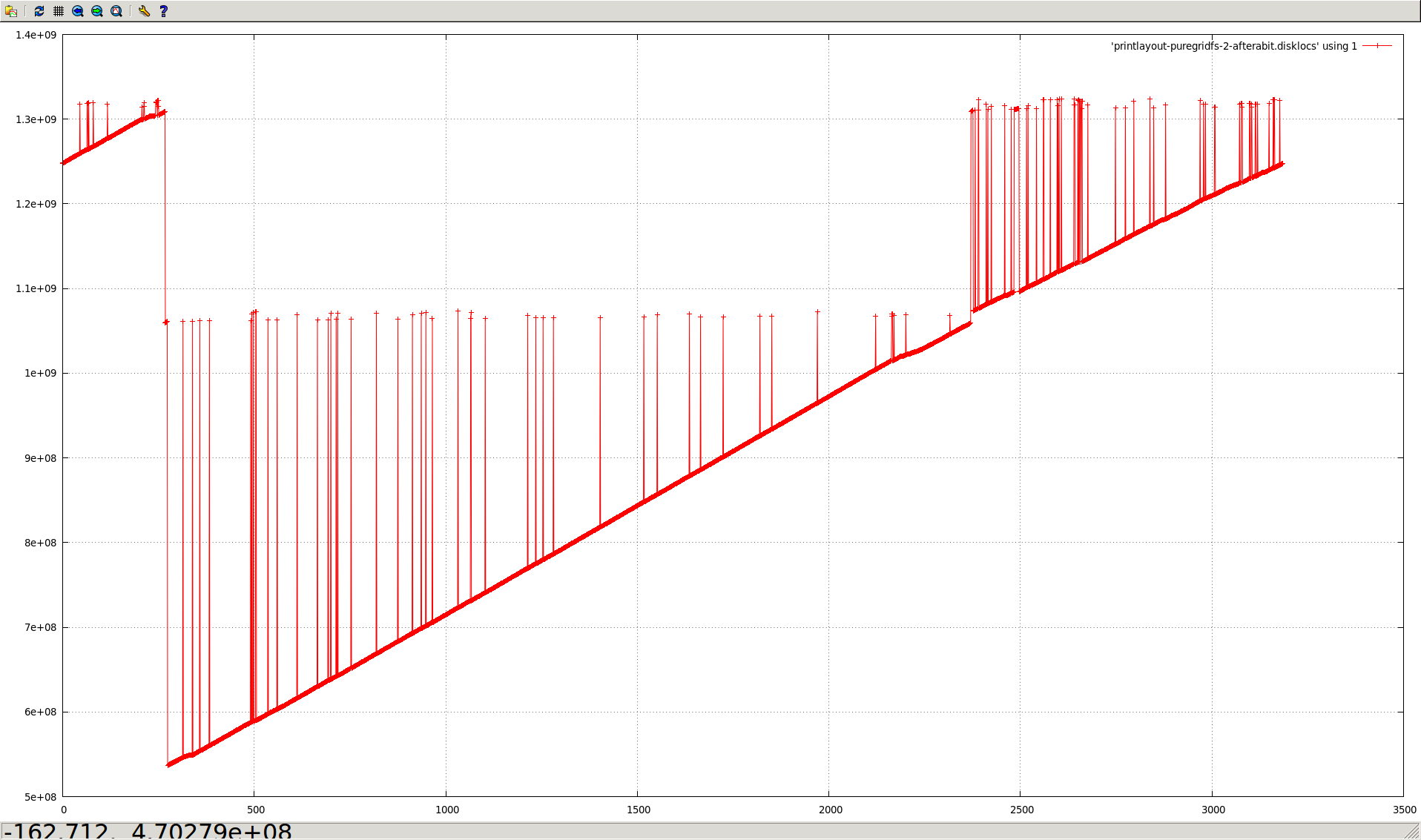
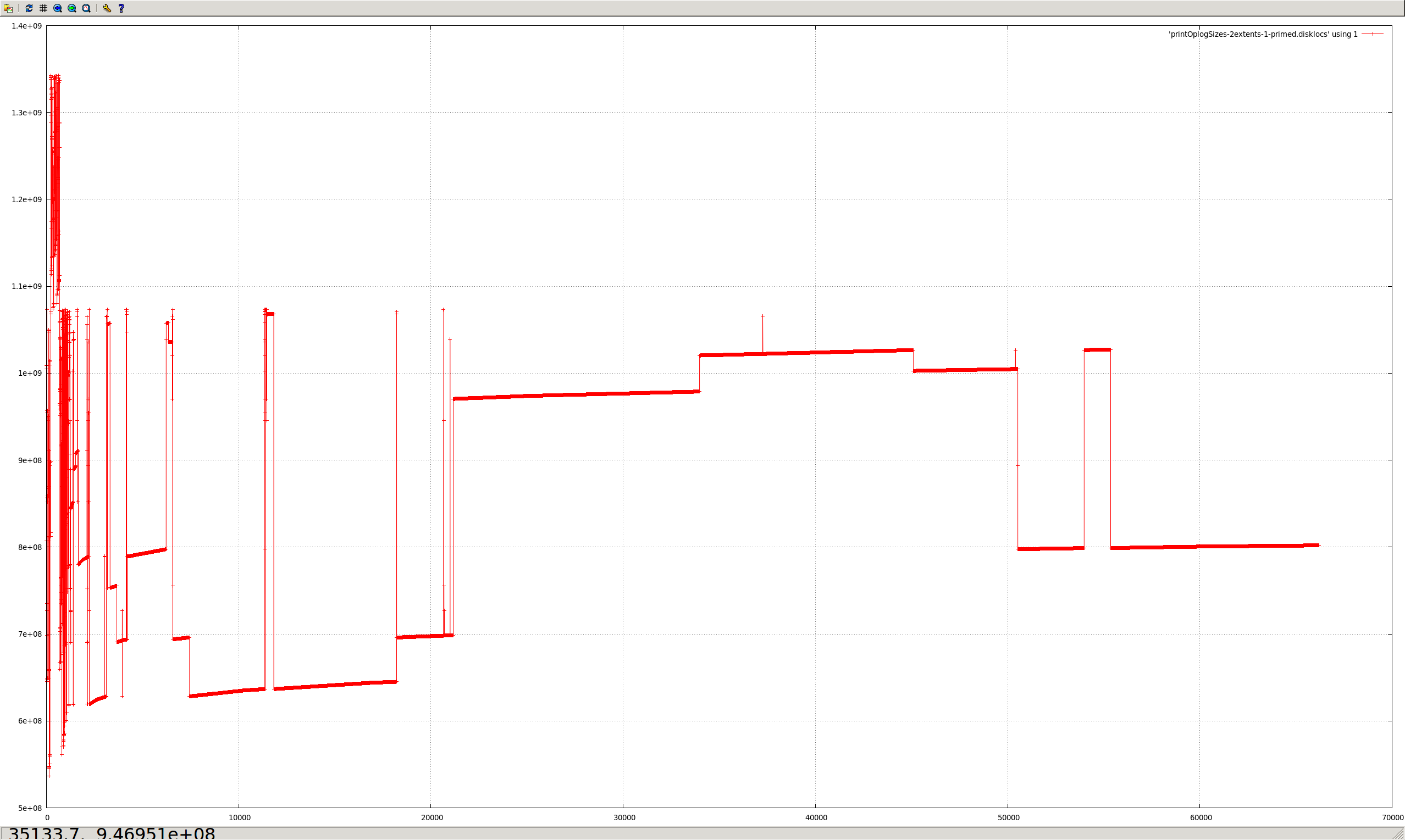
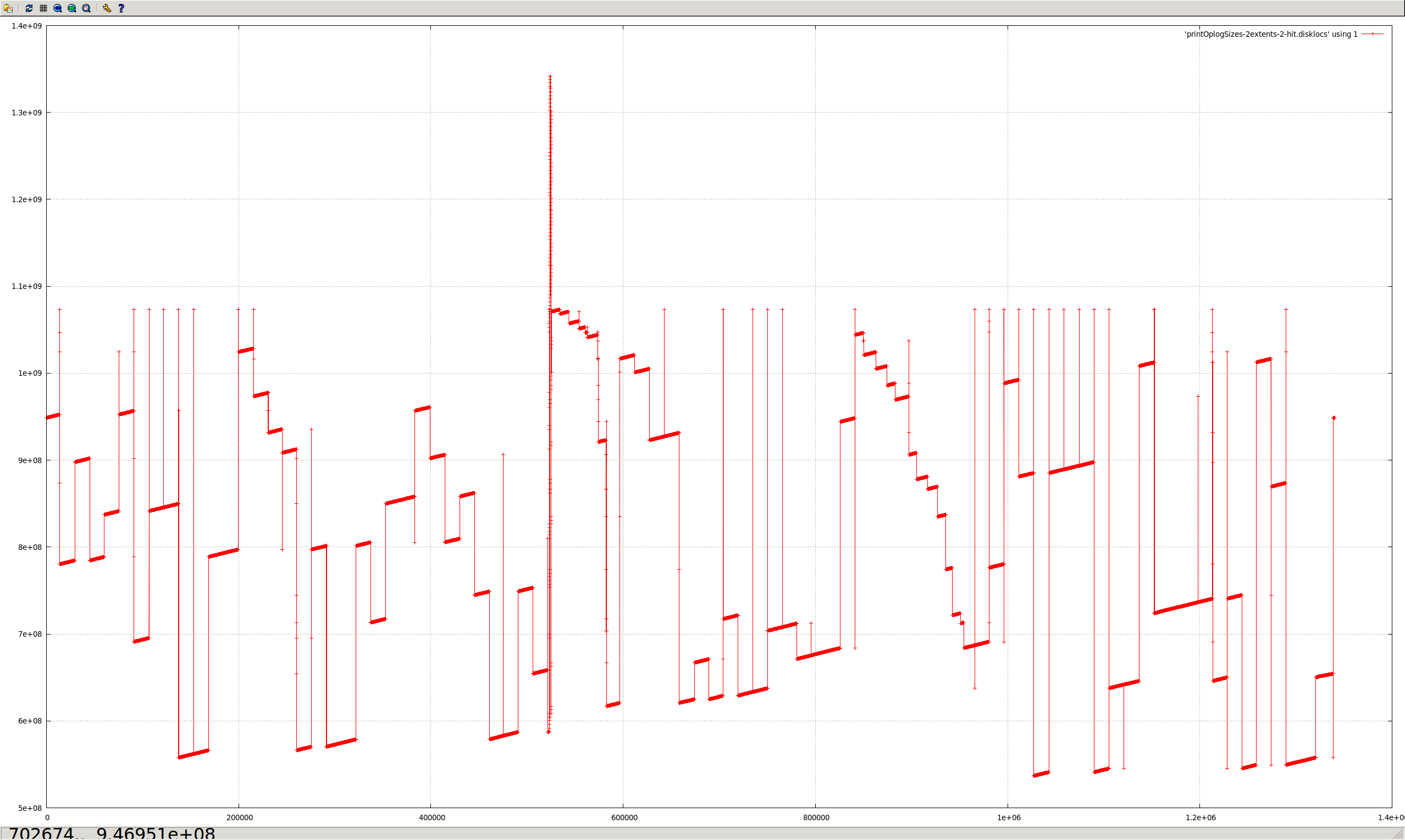
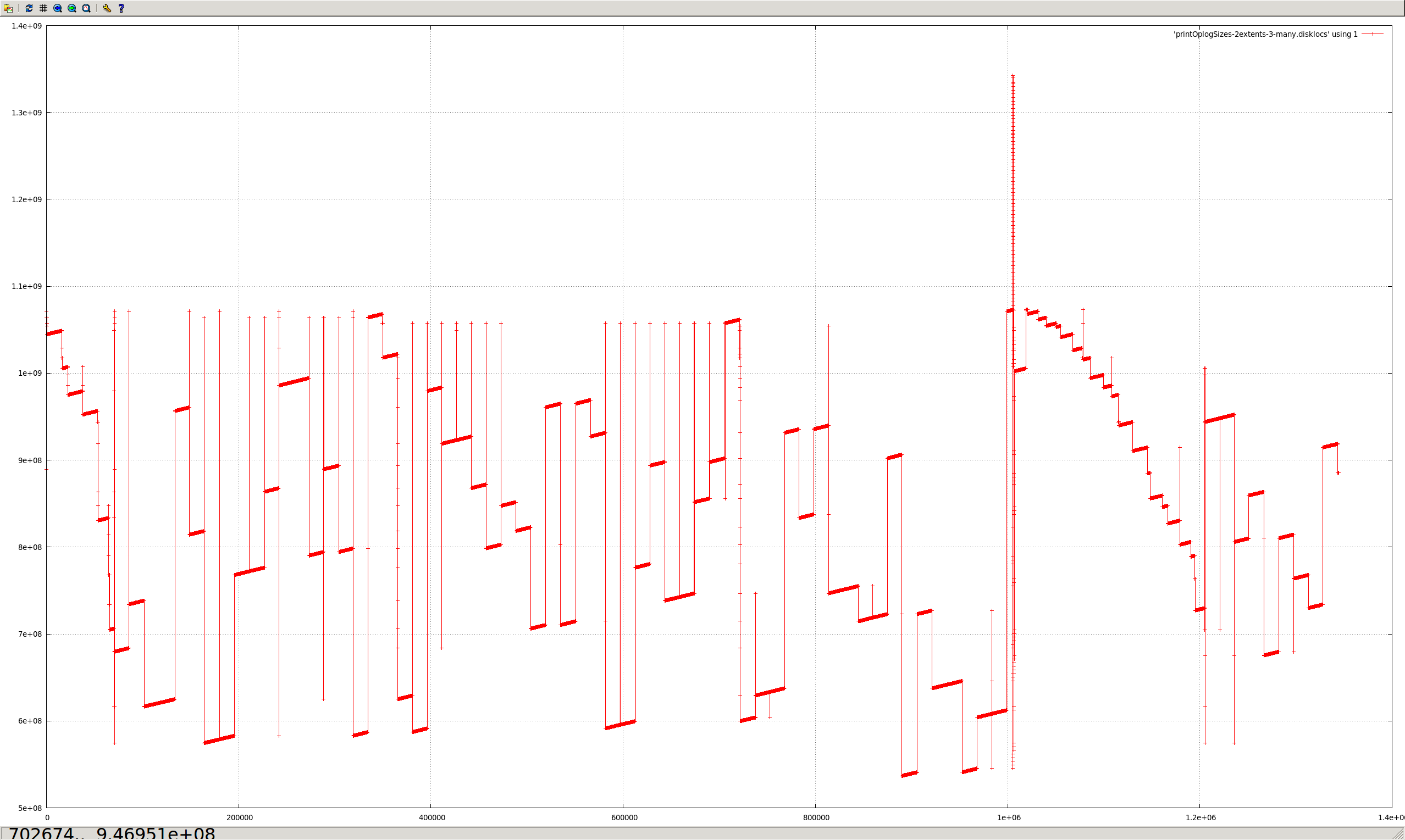
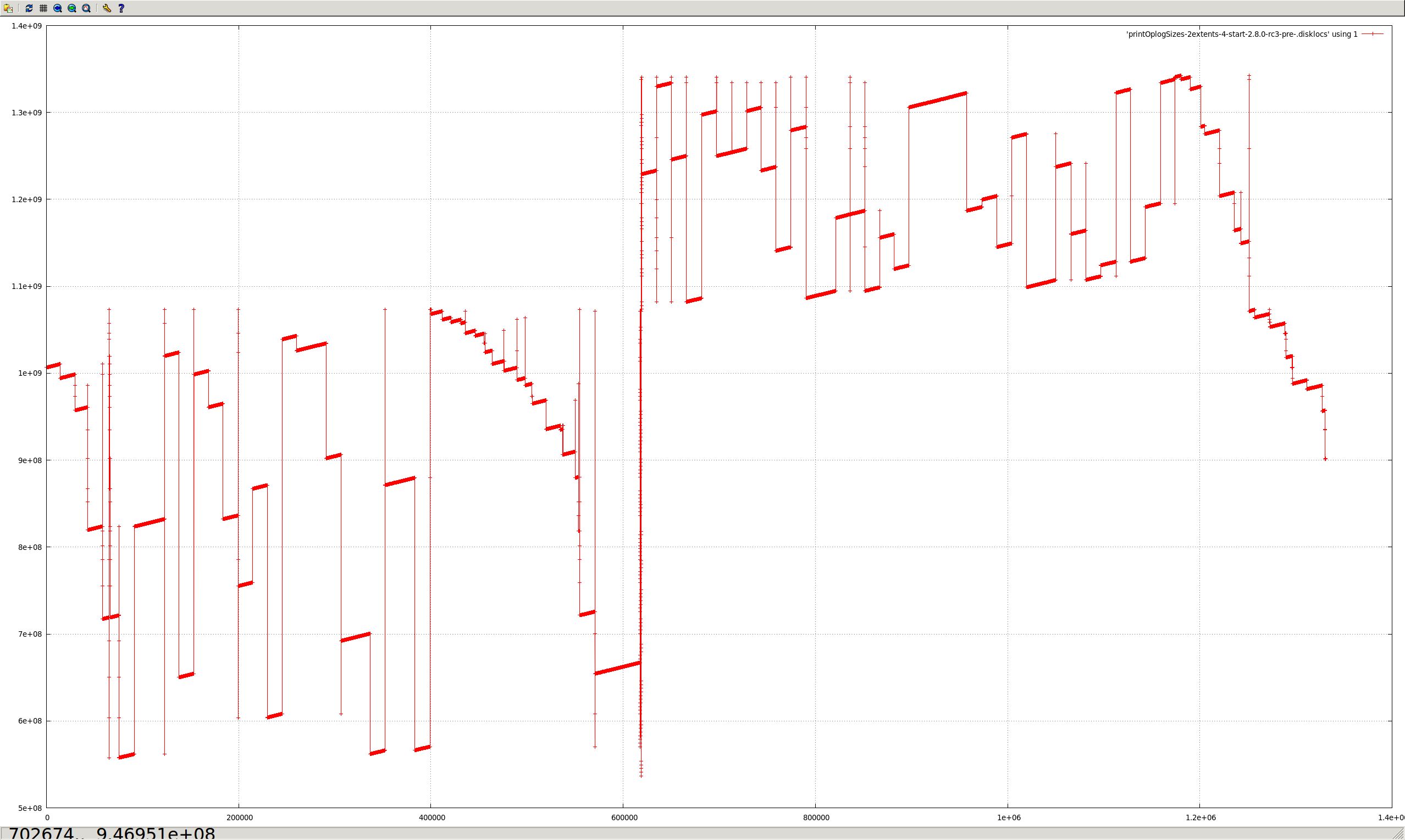
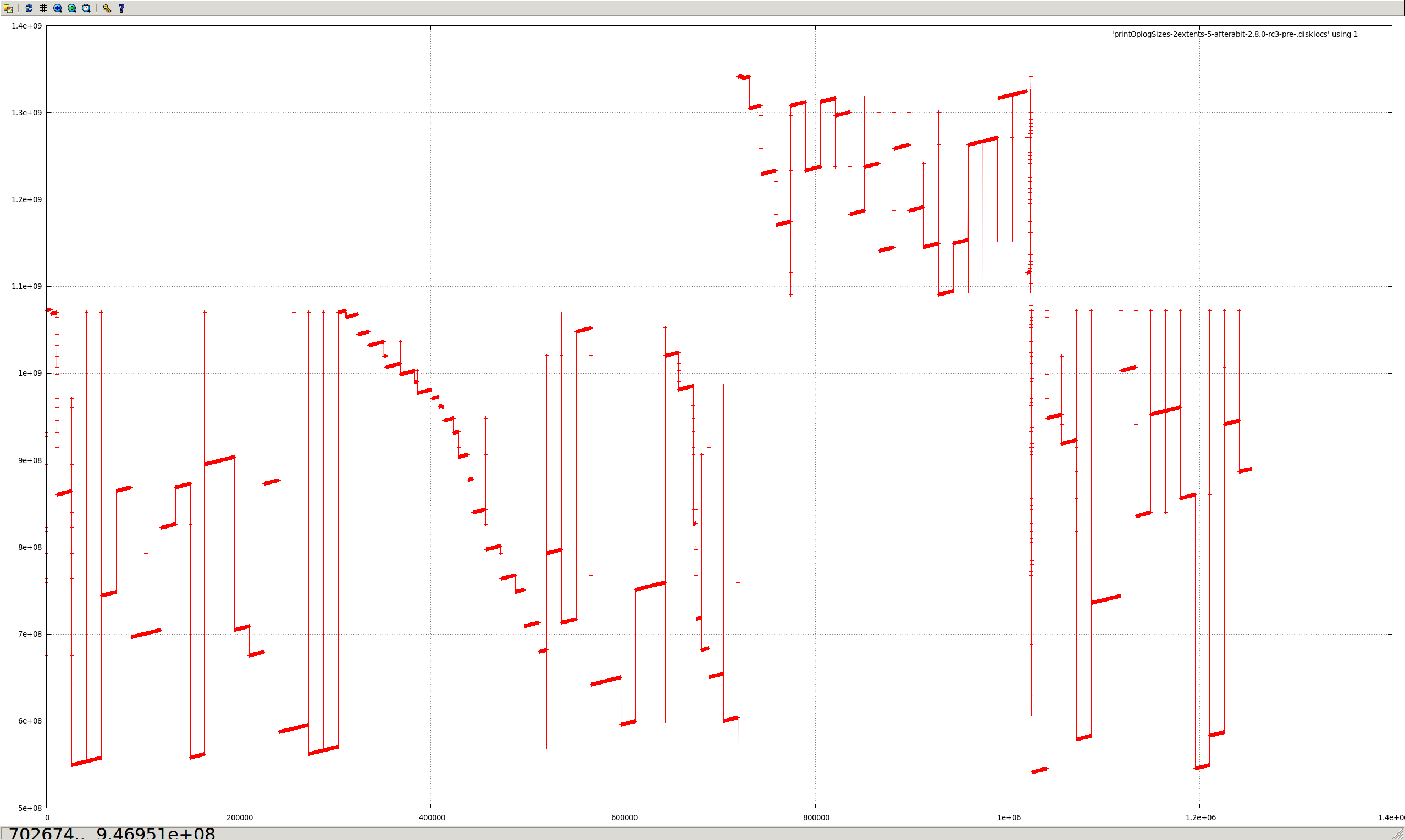
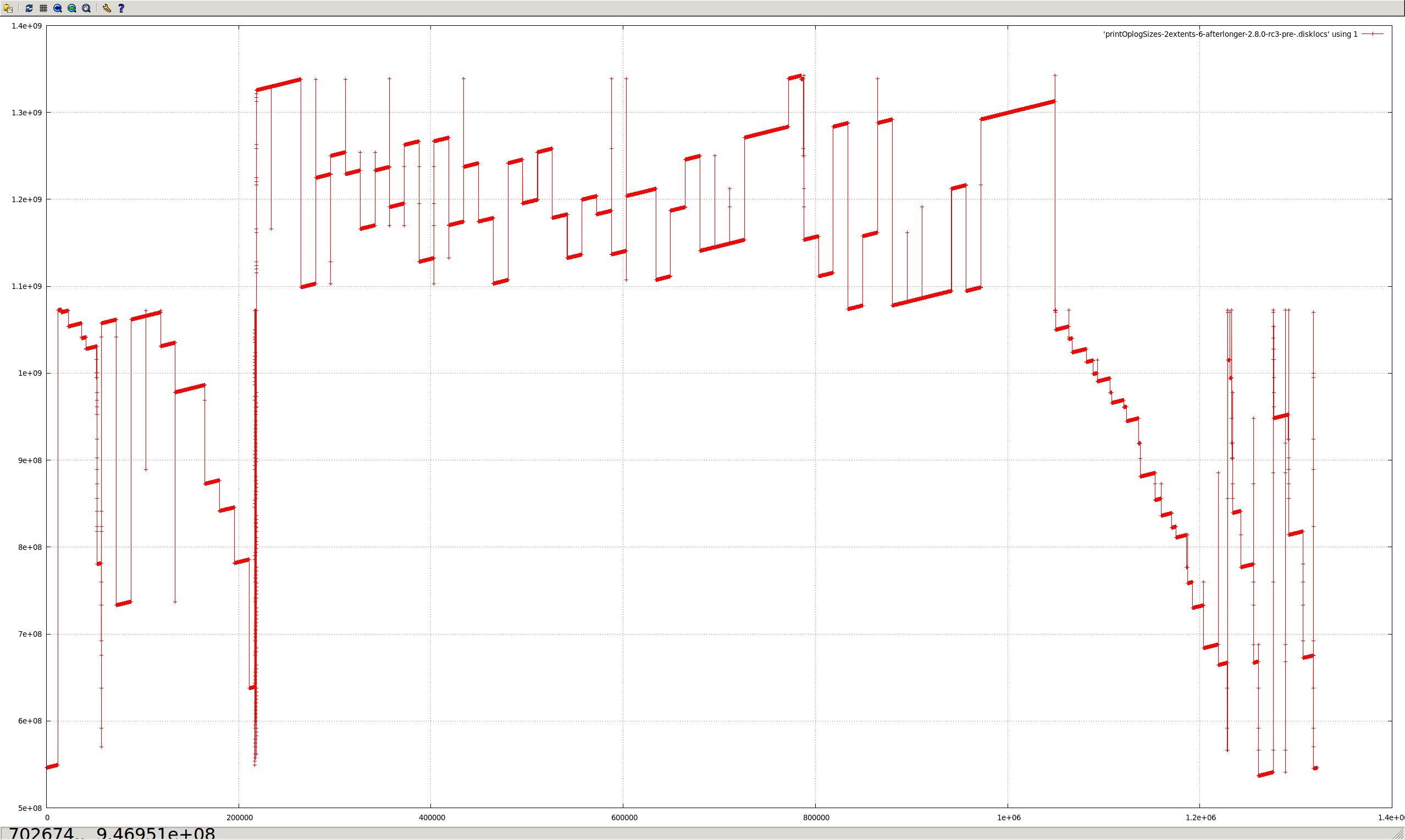
Capped collections (mmapv1) do not necessarily store documents linearly (both within extents, and from extent to extent).
Aside from the substantial shock to the "ring buffer" mental model commonly used for capped collections, this directly causes poor performance in (at least) two regards:
- Insertion time, because too many documents need to be deleted.
- Fragmented natural order causes non-linear page access, and hence more paging/IO than might otherwise be necessary.
The situation is worsened by severely heterogenous document sizes. It occurs least when every document is the exact same size.
The issue is important because for replication, the oplog is a single point of contention that can't be worked around.
Impact
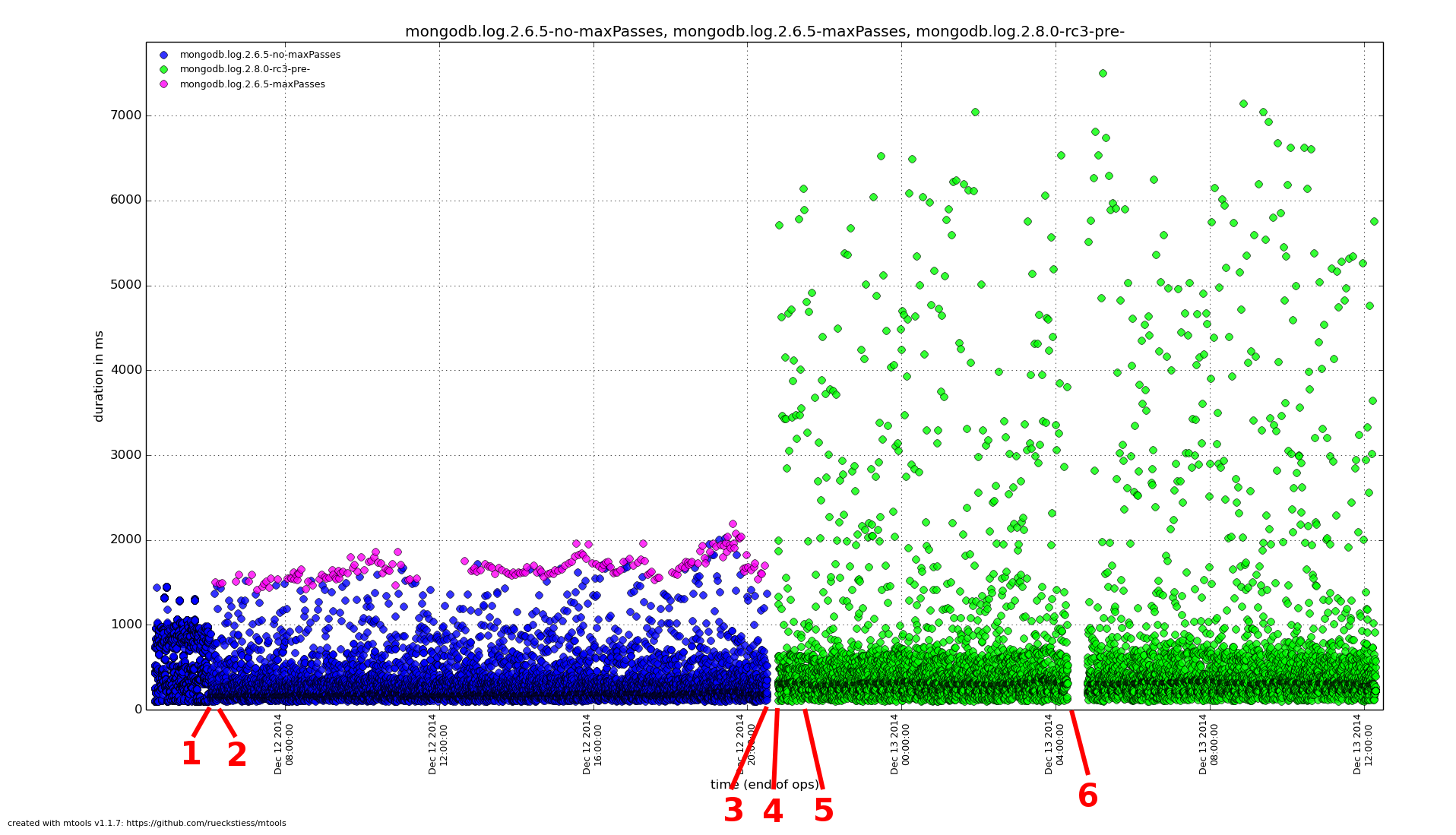
Prior to the SERVER-6981 fix, this issue caused the insert to fail with the exception "passes >= maxPasses in NamespaceDetails::cappedAlloc". If this happened on the oplog, then prior to SERVER-12058 being fixed (in 2.6.6), the oplog was rendered inconsistent. After SERVER-12058, the server would instead fassert if the oplog insert failed.
The fix for SERVER-6981 removed the assertion, but does not address the root cause of capped collection fragmentation. The fix there is to simply keep removing documents until the new one can be inserted, potentially causing very many "extra" removes to occur. This might cause performance problems, since previously maxPasses limited the runtime. There is also the (unknown) possible side-effect of permitting the fragmentation to worsen unbounded (where previously maxPasses limited it). SERVER-6981 has 3 duplicates, most notably SERVER-15265.
Unfortunately, as the results below show, although the fix in SERVER-6981 is necessary to address the problem, it is not sufficient. (Although the results below mix versions, I also tested from-scratch the version with SERVER-6981 fixed, and the results were the same.)
Cause?
I believe the reason for this is that CappedRecordStoreV1::allocRecord (previously cappedAlloc) uses the freelist to find a suitably sized record. After the first pass through, if none is found, then a document is removed from the front of the capped collection (in natural order), and it tries again. But the found record might be much earlier or later in the extent, or in another extent completely (perhaps — there does seem to be some code guarding against this, in at least some cases).
The approach of removing documents in natural order to "make space" seems to assume they are in a strict linear order. However, this isn't the case, because the space near the end of extents can only be used by small documents (larger documents must go in the next extent).
Suggested fix
One possible approach to fix this is for MMAPv1 capped collections to have a purely linear allocation strategy (even after the collection wraps around). For example, an algorithm something like:
- Find the "next" position where a new record can be stored. (i.e. at the "end" of the collection, after the final record, in natural order.)
- Will the incoming document will fit between this point and the end of the extent?
- If so, then use this point as the start of the new record.
- If not, then use the start of the next extent as the start of the new record.
- Either way, traverse the existing documents from the start of the collection, removing them from the record linked lists (but not freelisting them), until the current position - start position for new record >= new record length (i.e. enough space has been cleared for the incoming record).
- Write the incoming record (over the top of the old data) and add it to the linked lists (i.e. just put it there, don't look up freelists).
Pros:
- Closer to the actual intention of the MMAPv1 capped allocation code (I believe).
- Closer to the common "ring buffer" mental model.
- Capped insertion would be constant time (well, linear in the size of the inserted document, of course).
- Potentially much simpler code.
- All of the messy fragmented capped collections shown in the graphs above would not occur.
Cons:
- Some wasted space at the end of extents (worst case only ~16MB out of every 512MB (~3%)).
- Large, invasive, and potentially hard-to-test change.


- related to
-
-
- Closed
-
-
SERVER-12058 Primary should abort if encountered problems writing to the oplog
-
- Closed
-