-
Type:
Bug
-
Resolution: Done
-
Priority:
 Major - P3
Major - P3
-
Affects Version/s: 2.6.7
-
Component/s: Replication
-
None
-
Minor Change
-
ALL
-
-
(copied to CRM)
-
None
-
None
-
None
-
None
-
None
-
None
-
None
Hello, everyone! Hope you're having a terrific week. ![]()
I think I may have found a thing!
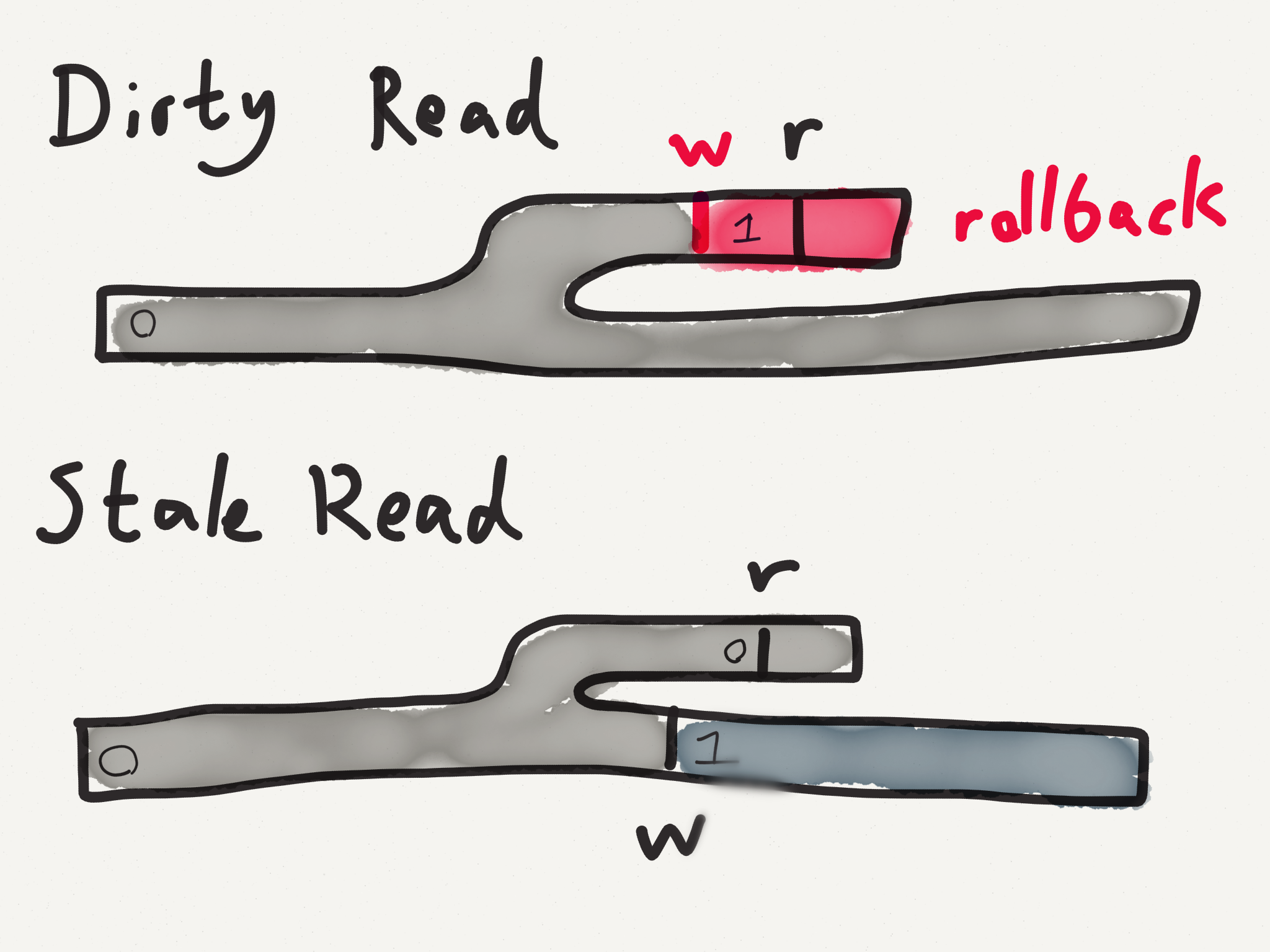
In Jepsen tests involving a mix of reads, writes, and compare-and-set against a single document, MongoDB appears to allow stale reads, even when writes use WriteConcern.MAJORITY, when network partitions cause a leader election. This holds for both plain find-by-id lookups and for queries explicitly passing ReadPreference.primary().
Here's how we execute read, write, and compare-and-set operations against a register:
And this is the schedule for failures: a 60-second on, 60-second off pattern of network partitions cutting the network cleanly into a randomly selected 3-node majority component and a 2-node minority component.
This particular test is a bit finicky--it's easy to get knossos locked into a really slow verification cycle, or to have trouble triggering the bug. Wish I had a more reliable test for you!
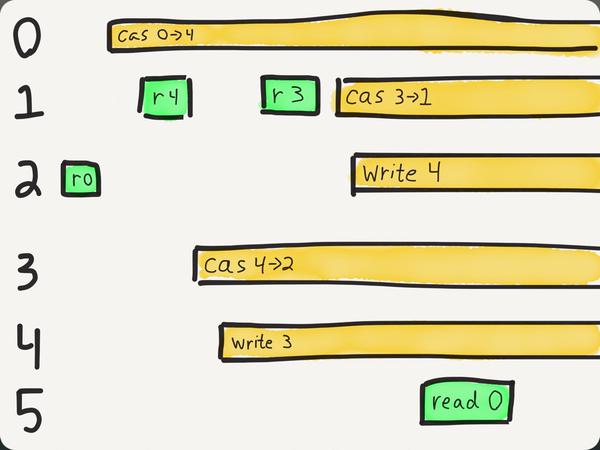
Attached, linearizability.txt shows the linearizability analysis from Knossos for a test run with a relatively simple failure mode. In this test, MongoDB returns the value "0" for the document, even though the only possible values for the document at that time were 1, 2, 3, or 4. The value 0 was the proper state at some time close to the partition's beginning, but successful reads just after the partition was fully established indicated that at least one of the indeterminate (:info) CaS operations changing the value away from 0 had to have executed.
You can see this visually in the attached image, where I've drawn the acknowledged (:ok) operations as green and indeterminate (:info) operations as yellow bars; omitting :fail ops which are known to have not taken place. Time moves from left to right; each process is a numbered horizontal track. The value must be zero just prior to the partition, but in order to read 4 and 3 we must execute process 1's CAS from 0->4; all possible paths from that point on cannot result in a value of 0 in time for process 5's final read.
Since the MongoDB docs for Read Preferences (http://docs.mongodb.org/manual/core/read-preference/) say "reading from the primary guarantees that read operations reflect the latest version of a document", I suspect this behavior conflicts with Mongo's intended behavior.
There is good news! If you remove all read operations from the mix, performing only CaS and writes, single-register ops with WriteConcern MAJORITY do appear to be linearizable! Or, at least, I haven't devised an aggressive enough test to expose any faults yet. ![]()
This suggests to me that MongoDB might make the same mistake that Etcd and Consul did with respect to consistent reads: assuming that a node which believes it is currently a primary can safely service a read request without confirming with a quorum of secondaries that it is still the primary. If this is so, you might refer to https://github.com/coreos/etcd/issues/741 and https://gist.github.com/armon/11059431 for more context on why this behavior is not consistent.
If this is the case, I think you can recover linearizable reads by computing the return value for the query, then verifying with a majority of nodes that no leadership transitions have happened since the start of the query, and then sending the result back to the client--preventing a logically "old" primary from servicing reads.
Let me know if there's anything else I can help with! ![]()
- depends on
-
SERVER-18285 Support linearizable reads on replica set primaries
-
- Closed
-
- related to
-
-
- Closed
-
-
-
- Closed
-