-
Type:
Bug
-
Resolution: Done
-
Priority:
 Critical - P2
Critical - P2
-
Affects Version/s: 3.0.1
-
Component/s: WiredTiger
-
Fully Compatible
-
Windows
-
Platform 3 05/15/15
-
None
-
0
-
None
-
None
-
None
-
None
-
None
-
None
The Windows Heap is implemented in user-space as part of kernel32.dll. It divides the heap into two portions:
- the Low-Fragmentation Heap (LFH) which is optimized for allocations < 16 KB
- the large allocation portion which takes a CriticalSection for each allocation and free.
When WiredTiger needs to make many allocations >= 16KB performance on Windows will to suffer once the WT cache fills up. This is easily triggered by workloads with large documents.
The solution we're pursuing is to use tc_malloc in place of the system allocator for WT on windows.
See below for more details and the original bug report.
Original Description

- At D performance drops and remains low for the second half of the run (first row).
- This coincides with the oplog reaching capacity (second row).
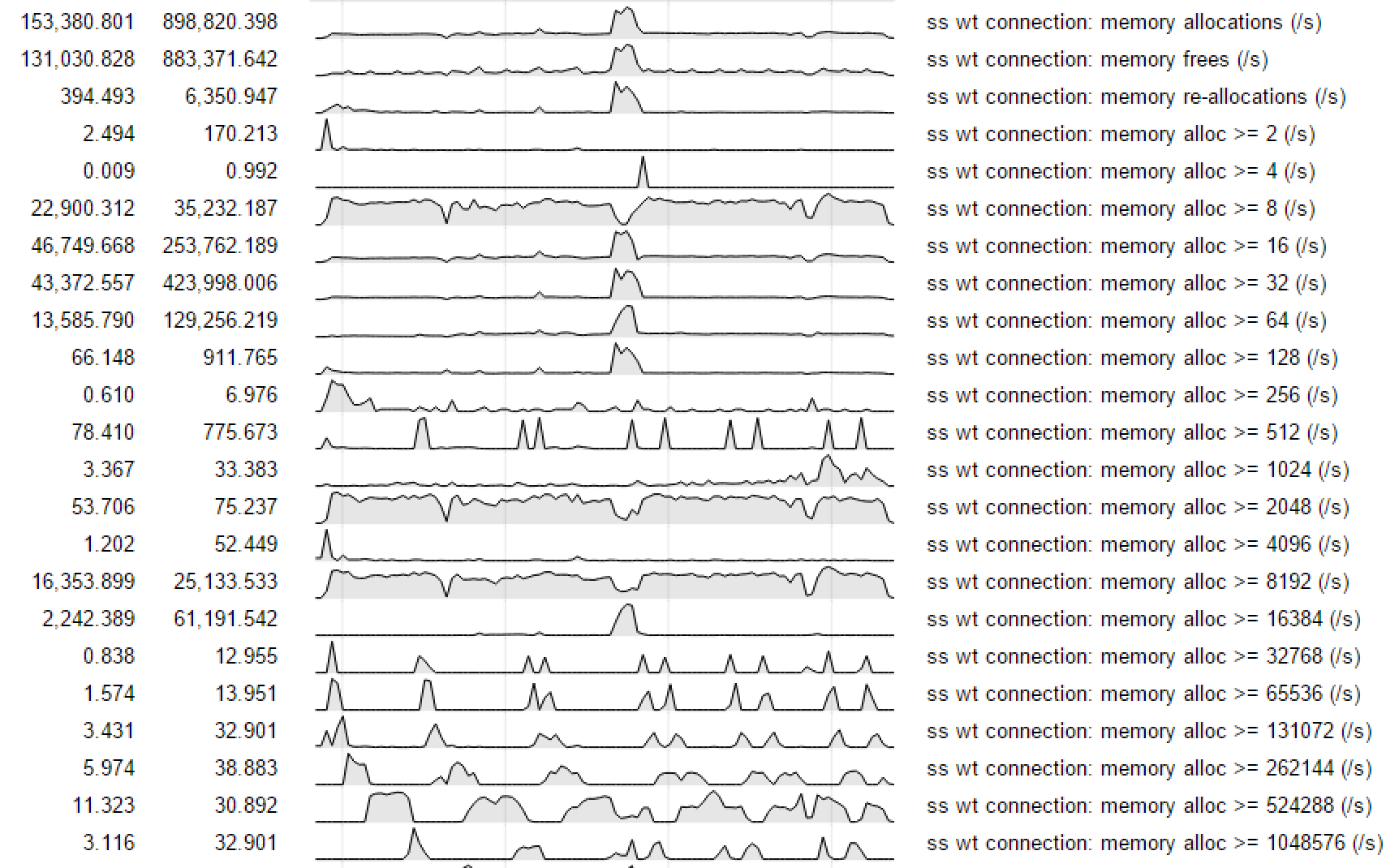
- It also coincides with an increase in heap lock contention (third row), presumably related to the increased memory allocator activity caused by deleting entries from the oplog. Note that heap lock contention has about doubled in spite of the operation rate having fallen by about 4x.
- A couple of other momentary dips in performance (A, B, C) appear to be related to disk activity (last two rows), and in fact heap lock contention fell during those dips because of the reduced op rate.
Interestingly, the drop is much more pronounced with a 2-node replica set than it is with a 1-node replica set (write concern 1 in both cases). The stack traces confirm the contention and show why a 2-node replica set is worse:
During the second half of the run there are significant periods when all 10 threads are waiting for the oplog deleter thread to reduce the size of the oplog:

The oplog deleter thread is held up by significant contention in the allocator, in 3 different places:

A primary source of contention seems to be the getmore that is tailing the oplog, which explains why a 2-node replica set is worse. Note that the oplog tail getmore is having to page in the entries even though they are brand new, which explains why it generates contention, but that seems non-optimal in itself, independent of the allocator issues.

Repro takes about 3 minutes (Windows on VMware instance, 6 cpus, 12 GB memory). Initialize 2-node replica set with these options:
mongod --storageEngine wiredTiger --wiredTigerCacheSizeGB 5 --oplogSize 6000 ...
Then run 10 threads of the following, which runs twice as long as it takes for the oplog to fill in order to generate a good comparison.
size = 16000
w = 1
batch = 10
function insert() {
x = ''
for (var i=0; i<size; i++)
x = x + 'x'
finish = 0
start = t = ISODate().getTime()
for (var i=0; finish==0 || t<finish; ) {
var bulk = db.c.initializeUnorderedBulkOp();
for (var j=0; j<batch; j++, i++)
bulk.insert({x:x})
bulk.execute({w:w});
t = ISODate().getTime()
if (i>0 && i%1000==0) {
var s = db.getSiblingDB('local').oplog.rs.stats(1024*1024)
print(i, s.size)
if (finish==0 && s.size>s.maxSize*0.9) {
finish = start + 2*(t-start)
print('finishing in', finish-t, 'ms')
}
}
}
}





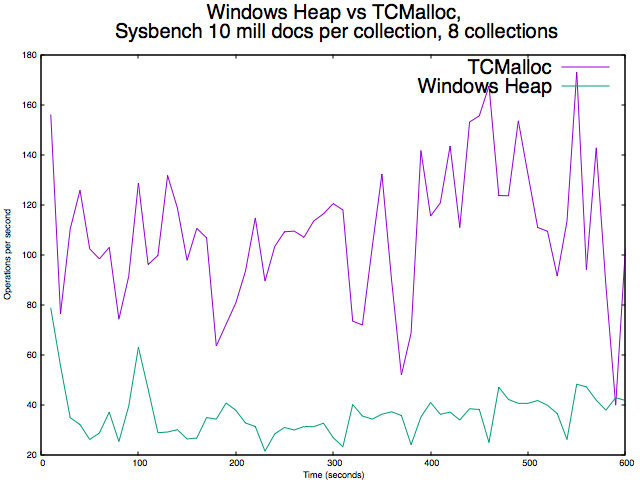


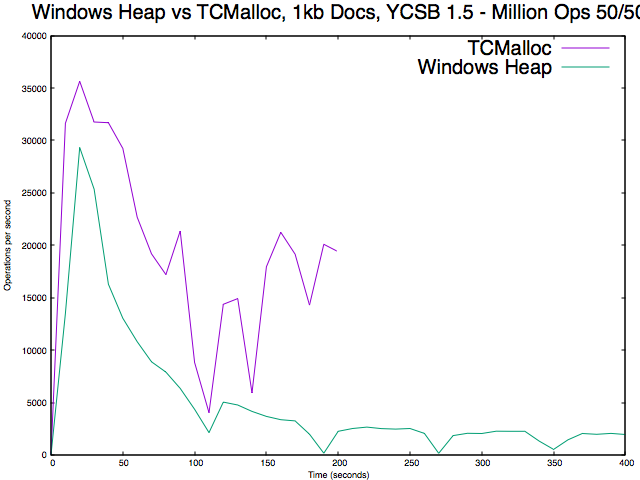
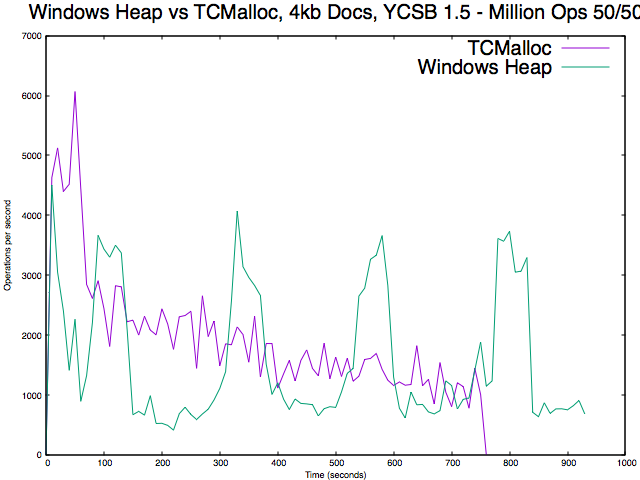
- is depended on by
-
-

- Closed
-
- is related to
-
-
- Closed
-
- related to
-
-
- Open
-
-
-
- Closed
-