I added the read role to the local database to workaround MMS-2240.
For a simple 3 node replicaset, on the primary I did this:
use admin db.updateUser('mongo-mms', {"roles" : [ { "role" : "clusterMonitor", "db" : "admin" }, {"role": "read", "db": "local"} ]}) centaurd:PRIMARY> db.system.users.find() ... { "_id" : "admin.mongo-mms", "user" : "mongo-mms", "db" : "admin", "credentials" : { "SCRAM-SHA-1" : { "iterationCount" : 10000, "salt" : "QujDz6Fl67kimiVH9WohLg==", "storedKey" : "BtDWckJVHLOF6Y/LaeUMuzRBI/0=", "serverKey" : "0GNKkjRRKddCUrIY+/wL0o2C4aY=" } }, "roles" : [ { "role" : "clusterMonitor", "db" : "admin" }, { "role" : "read", "db" : "local" } ] } ...
Almost immediately the problem was resolved on the primary:
2015-05-01T11:41:07.349+0100 I ACCESS [conn28532] Successfully authenticated as principal mongo-mms on admin
2015-05-01T11:41:16.064+0100 I NETWORK [conn28530] end connection 10.220.54.121:38399 (10 connections now open)
2015-05-01T11:41:16.064+0100 I NETWORK [initandlisten] connection accepted from 10.220.54.121:38470 #28533 (12 connections now o
pen)
2015-05-01T11:41:16.072+0100 I NETWORK [conn28531] end connection 10.220.54.122:36979 (10 connections now open)
2015-05-01T11:41:16.076+0100 I NETWORK [initandlisten] connection accepted from 10.220.54.122:37024 #28534 (11 connections now o
pen)
2015-05-01T11:41:16.083+0100 I ACCESS [conn28533] Successfully authenticated as principal __system on local
2015-05-01T11:41:16.094+0100 I ACCESS [conn28534] Successfully authenticated as principal __system on local
2015-05-01T11:41:22.077+0100 I QUERY [conn28437] assertion 13 not authorized for query on local.oplog.rs ns:local.oplog.rs que
ry:{ $query: {}, $orderby: { $natural: 1 } }
2015-05-01T11:41:22.077+0100 I QUERY [conn28437] ntoskip:0 ntoreturn:-1
2015-05-01T11:41:46.097+0100 I NETWORK [conn28533] end connection 10.220.54.121:38470 (10 connections now open)
2015-05-01T11:41:46.097+0100 I NETWORK [initandlisten] connection accepted from 10.220.54.121:38542 #28535 (12 connections now o
pen)
2015-05-01T11:41:46.106+0100 I NETWORK [conn28534] end connection 10.220.54.122:37024 (10 connections now open)
2015-05-01T11:41:46.109+0100 I NETWORK [initandlisten] connection accepted from 10.220.54.122:37065 #28536 (12 connections now o
pen)
2015-05-01T11:41:46.115+0100 I ACCESS [conn28535] Successfully authenticated as principal __system on local
2015-05-01T11:41:46.127+0100 I ACCESS [conn28536] Successfully authenticated as principal __system on local
2015-05-01T11:42:16.133+0100 I NETWORK [conn28535] end connection 10.220.54.121:38542 (10 connections now open)
2015-05-01T11:42:16.136+0100 I NETWORK [conn28536] end connection 10.220.54.122:37065 (9 connections now open)
However the secondary logs continue to contain the not-authorized warnings for more than one hour after:
2015-05-01T13:10:17.059+0100 I ACCESS [conn27021] Successfully authenticated as principal __system on local
2015-05-01T13:10:27.653+0100 I QUERY [conn26950] assertion 13 not authorized for query on local.oplog.rs ns:local.oplog.rs query:{ $query: {}, $orderby: { $natural: 1 } }
2015-05-01T13:10:27.653+0100 I QUERY [conn26950] ntoskip:0 ntoreturn:-1
2015-05-01T13:10:46.746+0100 I NETWORK [conn27020] end connection 10.220.54.122:41619 (5 connections now open)
2015-05-01T13:10:46.747+0100 I NETWORK [initandlisten] connection accepted from 10.220.54.122:41659 #27022 (6 connections now open)
I verified that the secondary had replicated the creds:
* mongo centaur-2.dev.man.com centaurd:SECONDARY> db.setSlaveOk(true) centaurd:SECONDARY> db.system.users.find() { "_id" : "admin.mongo-mms", "user" : "mongo-mms", "db" : "admin", "credentials" : { "SCRAM-SHA-1" : { "iterationCount" : 10000, "salt" : "QujDz6Fl67kimiVH9WohLg==", "storedKey" : "BtDWckJVHLOF6Y/LaeUMuzRBI/0=", "serverKey" : "0GNKkjRRKddCUrIY+/wL0o2C4aY=" } }, "roles" : [ { "role" : "clusterMonitor", "db" : "admin" }, { "role" : "read", "db" : "local" } ] }
Restarting the secondary seems to fix the issue.
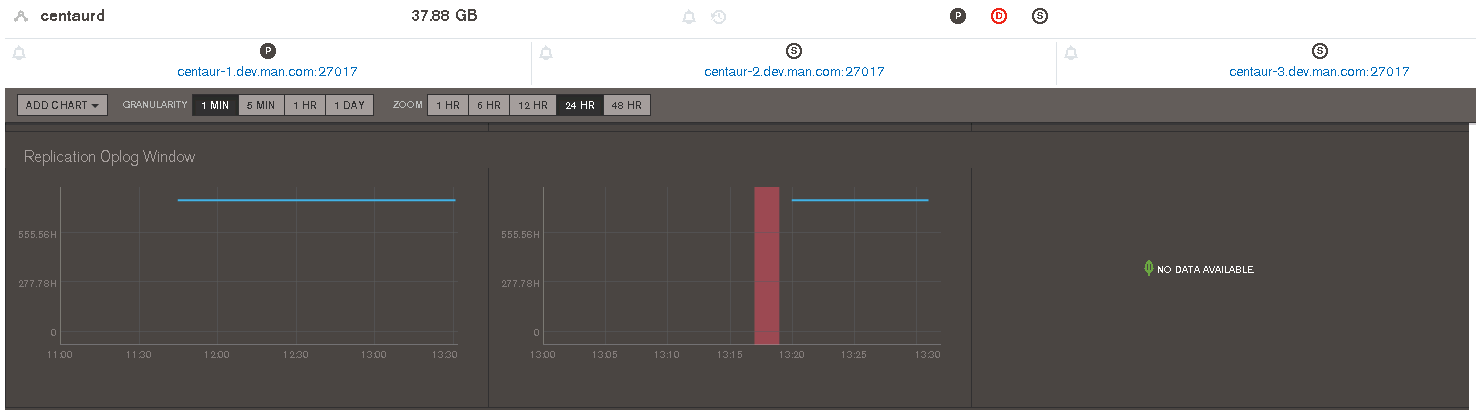
The issue is also visible in MMS in the centaurd cluster - the MMS agent starts detecting the oplog window for the primary immediately, but the secondary doesn't have this metric until restart. Screenshot attached.
{kind=link}
- is duplicated by
-
SERVER-18165 After changeUserPassword on replica master, slave`s authorizen only by old password
-

- Closed
-