-
Type:
Bug
-
Resolution: Done
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: 3.1.3
-
Component/s: WiredTiger
-
None
-
Fully Compatible
-
ALL
-
None
-
None
-
None
-
None
-
None
-
None
-
None
- 132 GB memory, 32 processors, slowish SSDs, 20 GB WT cache
- YCSB 10 fields/doc, 50/50 workload (zipfian distribution), 20 threads
- data set size varies - see tests below
- 10M docs, data set ~12 GB (but cache usage can be double that)
- 20M docs, data set ~23 GB (but cache usage can be double that)
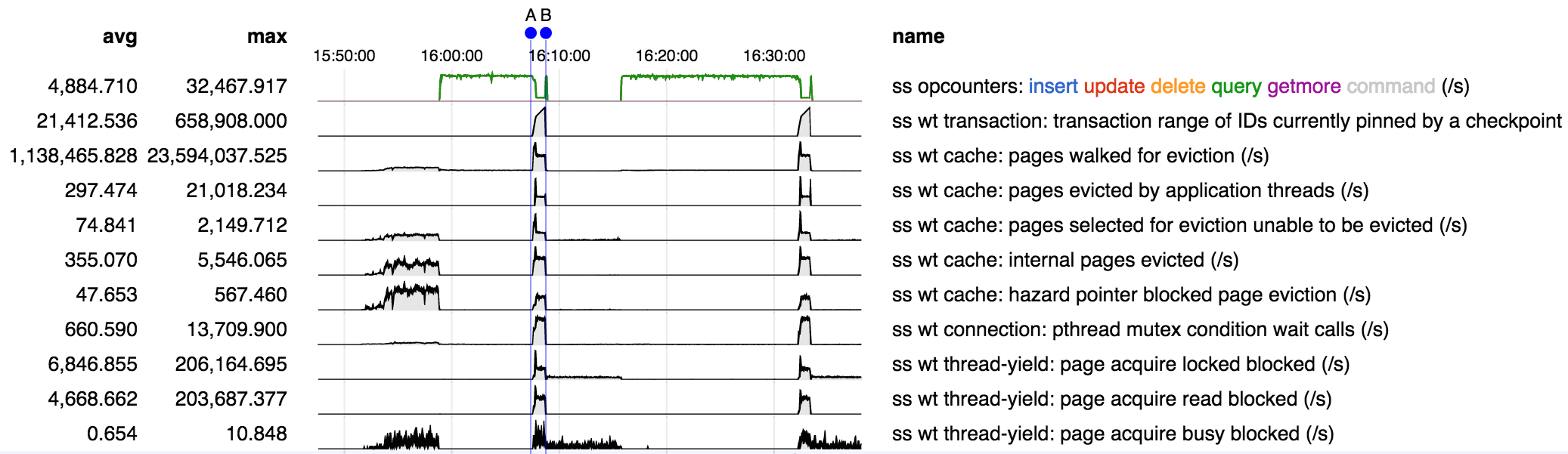
In SERVER-18315 an issue was reported in 3.0.2 during the "transaction pinned" phase of checkpoints (B-C) with a 10M document data set:

This was fixed in 3.1.3:

However if the data set is increased to 20M documents a similar problem still appears in 3.1.3. Based on the shapes of the curves it appears this may be a little different issue: in SERVER-18315 the throughput dropped in proportion to the rise in "range of transactions pinned" but that does not seem to be the case here.

(Note: C-D is a different issue - see SERVER-18674).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- is related to
-
-
- Closed
-
-
-
- Closed
-
- related to
-
-

- Closed
-
-
-
- Closed
-
-
WT-1907 Speed up transaction-refresh
-
- Closed
-