-
Type:
Bug
-
Resolution: Duplicate
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: 3.0.3
-
Component/s: Index Maintenance, WiredTiger
-
None
-
ALL
-
None
-
0
-
None
-
None
-
None
-
None
-
None
-
None
The hidden secondary server I use for backups cannot sync its data from the replica set. It's a replica set of 3 servers including the one which get killed by the kernel. All are running mongod 3.0.3.
I'm currently trying to migrate from mmapv1 to WiredTiger. The two main servers use mmapv1. The initial sync goes fine, copying our 292 million documents, mongod takes around 80% of the RAM. Then it starts building the index on _id. After a few %, the kernel kills mongod. I attached the logs from /var/log/messages.
If I relaunch mongod, it retries building the index, then exits because of (the famous ?):
Index Build "Index rebuilding did not complete: 11000 E11000 duplicate key error collection: rum.reports index: _id_ dup key: { : "11jjgtfncmtn9w47mco7vtbbj" }"
If I relaunch mongod with indexBuildRetry=false, it restarts cloning the collection from the beginning after showing:
_2015-06-05T16:17:37.683+0000 W REPL [ReplicationExecutor] Failed to load timestamp of most recently applied operation; NoMatchingDocument Did not find any entries in local.oplog.rs_
This server has only 16GB RAM, and can do a sync with mmapv1 without any problem. The database size is 946GB on mmapv1, and 243GB on WiredTiger (snappy).
I started running the following command when the cloning was at 236M docs. I attached the result.
mongo --eval "while(true) {print(JSON.stringify(db.serverStatus({tcmalloc:1}))); sleep(10*1000)}" > ss.log
Cloning finishes at 2015-06-05T16:09:38.003+0000.
Index creation starts at 2015-06-05T16:09:45.606+0000.
The last log before the kill:
2015-06-05T16:12:00.565+0000 I - [rsSync] Index Build: 13494400/292298635 4%
On another replica set, this migration worked fine with a database size of 402GB mmapv1 / 133GB WT. For the record, the sync also took all the RAM, but index creation went fine. What's interesting is that after a restart of mongod on this server, RAM usage went from 100% to 17%. After a few days of continuous writes from the oplog, it's now at 43% RAM. I did not launch any query or make any backup from this secondary.
The two replica sets contain the same kind of documents, and the same indexes.
My storage configuration:
storage:
dbPath: /a/b/c
indexBuildRetry: true
journal:
enabled: true
directoryPerDB: false # default
syncPeriodSecs: 60 # default
engine: wiredTiger
wiredTiger:
engineConfig:
# cacheSizeGB: 12 # Default: the maximum of half of physical RAM or 1 gigabyte.
statisticsLogDelaySecs: 0 # If set to 0, WiredTiger does not log statistics.
journalCompressor: snappy # Default: snappy
directoryForIndexes: false # Default: false
collectionConfig:
blockCompressor: snappy # Default: snappy
indexConfig:
prefixCompression: true # Default: true
There's this storage.wiredTiger.engineConfig.cacheSizeGB setting. I don't really get what it means. I tried setting the default, or setting it at 14. RAM usage still goes beyond the server capacity.
This issue could be related to SERVER-17456 and SERVER-17424. I created a new issue, because this one happens during an initial sync, not because of benchmarks.
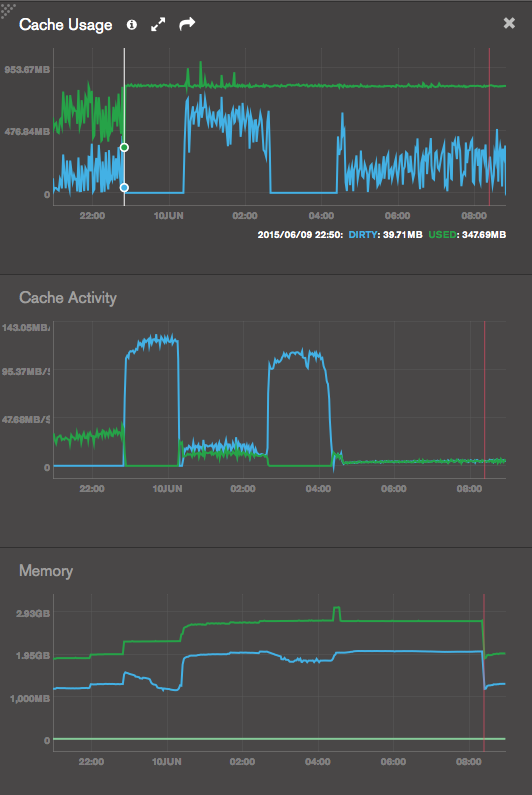
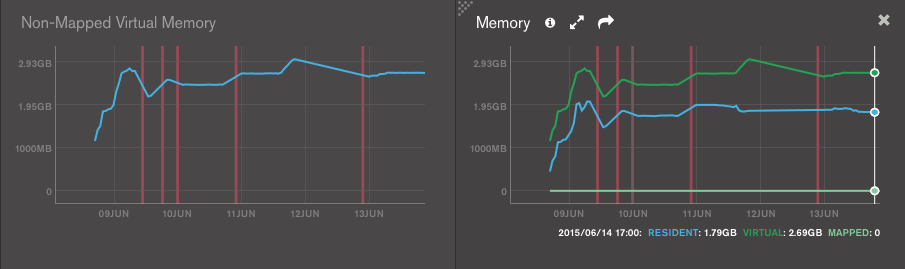
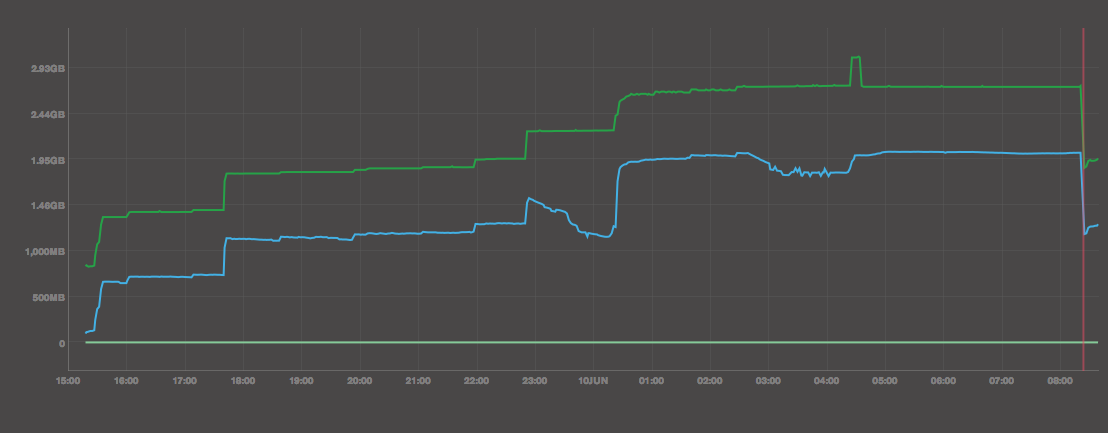
In case someone at MongoDB is interested, the servers are monitored by MMS:
- The failing group is 556dc2ffe4b0ba305ae49354. The hidden Secondary is the only one running on WiredTiger. It's the one that I try to sync again and again.
- The ok group is 556dce19e4b0eea5366e6ae5. The hidden Secondary is the only one running on WiredTiger.
- duplicates
-
-
- Closed
-