-
Type:
Bug
-
Resolution: Done
-
Priority:
 Critical - P2
Critical - P2
-
None
-
Affects Version/s: 3.0.6
-
Component/s: Replication
-
None
-
ALL
-
We have a sharded mongo cluster with 3 shards. Each shard contains two active members and an arbitrator. Most collections are sharded across this cluster.
For the past 2 weeks the secondary in shard 0 has continuously ended up stale. Every time this has happened we have been attempting to determine the cause of the replication error, without any luck.
Using the article https://docs.mongodb.org/manual/tutorial/troubleshoot-replica-sets/ we have ruled out the below causes of replication error (evidence included in this bug report).
All evidence covers the timespan of the last secondary failure which occurred at approx. 2015/11/17 20:23 GMT.
All times are UTC.
Network Latency
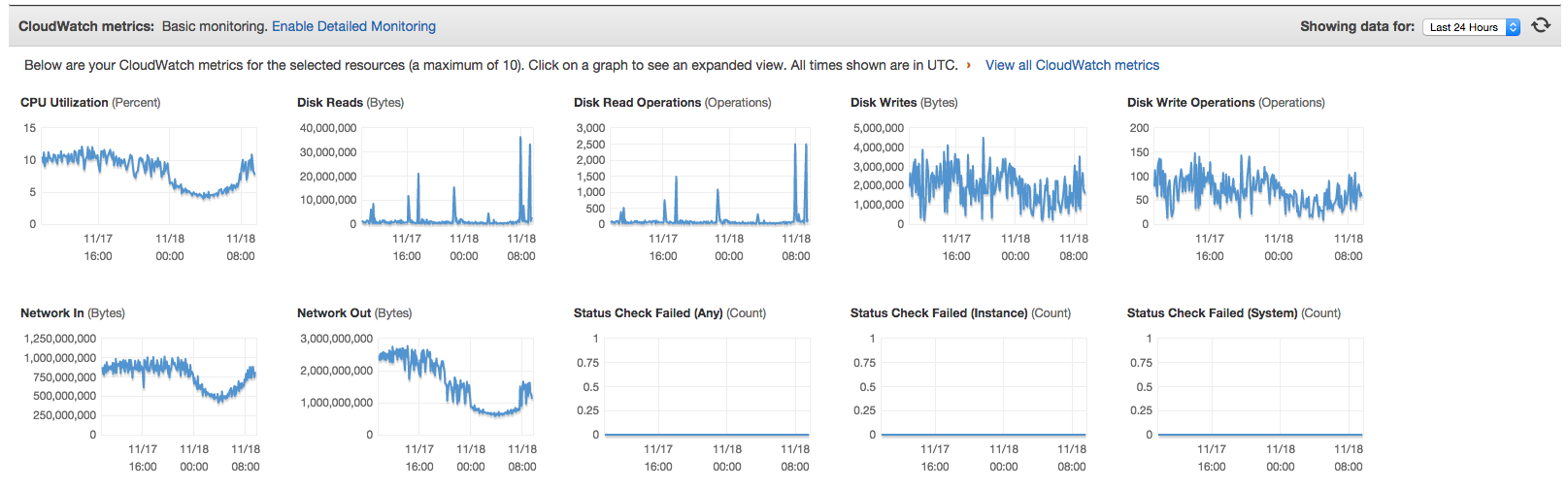
See attached RS0-Primary-Metrics.png & RS0-Secondary-Metrics.png
Network throughput between the instances was lower for the duration of this period than it is during initial sync.
Disk Throughput
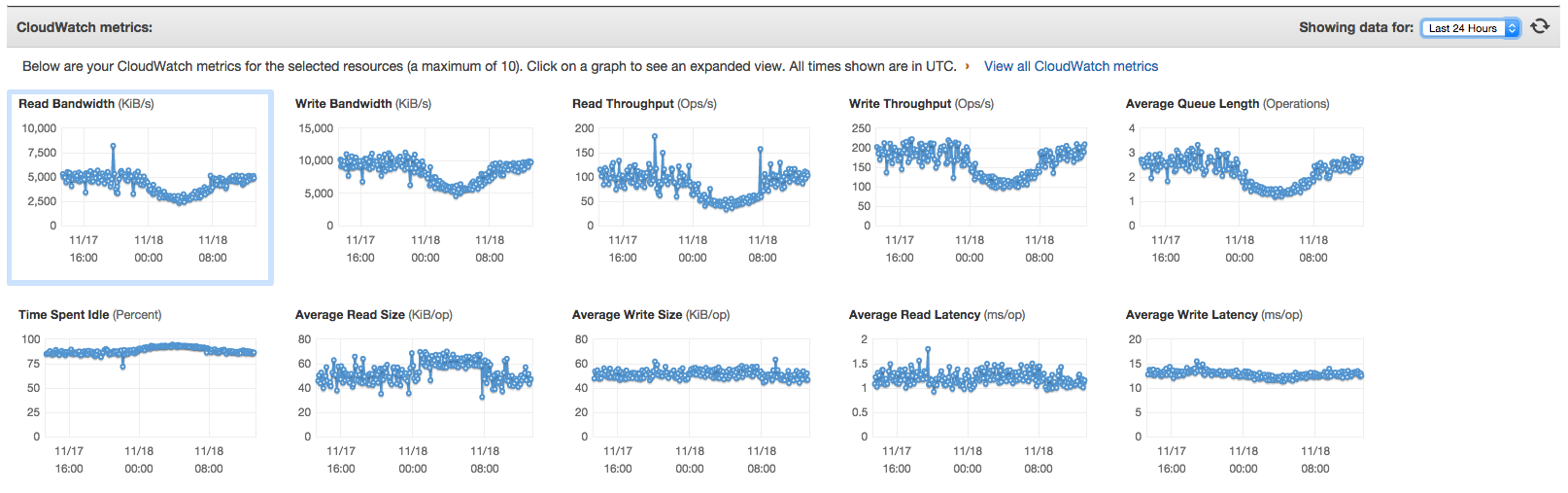
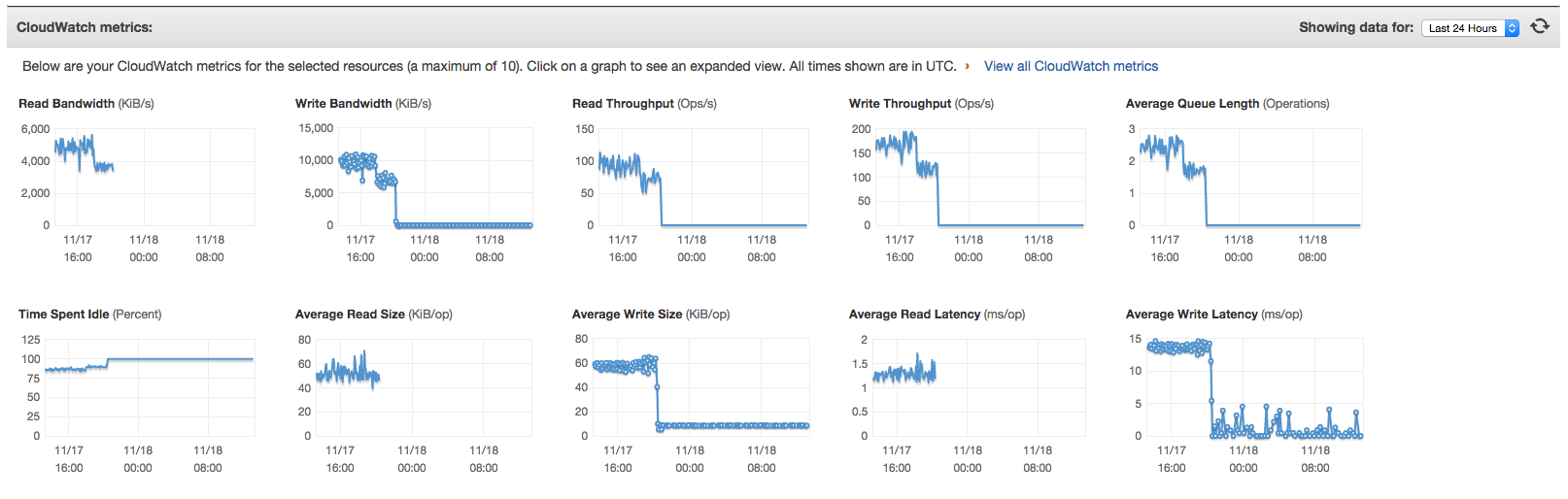
See attached RS0-Primary-MongoDiskMetrics.png & RS0-Secondary-MongoDiskMetrics.png
Disk throughout is limit to approx 750 total ops/s. Neither disk on the primary or secondary is reaching this limit.
Concurrency
See attached mongod_rs0_primary.log
There does not appear to be a higher than normal occurrence of slow queries or long-running operations over the period where the secondary becomes stale.
Appropriate Write Concern
Our data ingestion rate is relatively consistent and slowly varying over any 24 hours period.
The write concern used is always WriteConcern.ACKNOWLEDGED.
OpLog Size
See attached RS0-Primary-OplogLength.png & RS0-Primary-OplogLength.xlsx
The opLog length is never less than 30 minutes (equivalent to 30GB of allocated oplog space).
Configuration Setup
All instances in cluster are hosted on AWS using the m3.2xlarge instance size.
IP Addresses for the different cluster members are as follows:
Shard 0 (Contains unsharded collections)
Primary - 10.0.1.179
Secondary - 10.0.2.145
Arbiter - 10.0.1.109
Shard 1
Primary - 10.0.1.180
Secondary - 10.0.2.146
Arbiter - 10.0.1.108
Shard 2
Primary - 10.0.1.212
Secondary - 10.0.2.199
Arbiter - 10.0.1.246
The secondaries are configured out of the box, i.e. no reads are allowed from secondaries.
To date we have been unable to locate the cause of this replication issue. As such we would like to report the above as a bug in the hope that you might be able to either explain the issue or resolve the problem in an upcoming release.
For the time being when the replication fails we have just been performing an initial sync on the failed secondary.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}