-
Type:
Bug
-
Resolution: Done
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: 3.2.0
-
Component/s: WiredTiger
-
None
-
ALL
-
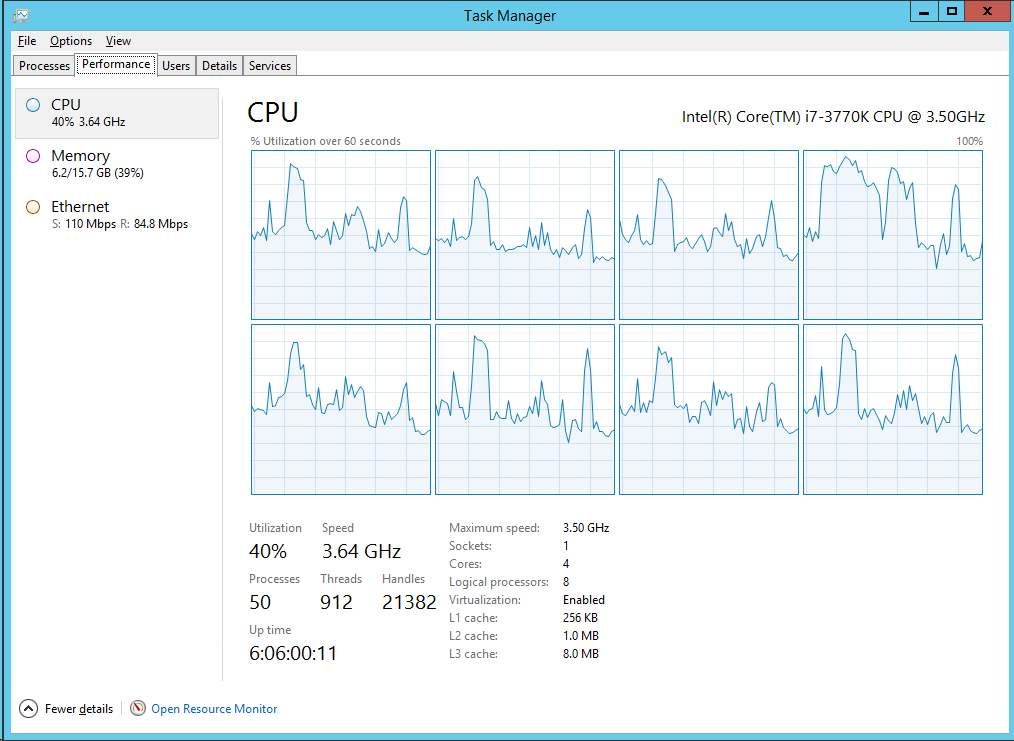
I'm playing with replica sets on 3.2. I have the following topology:
1 x i3770 with SSD [Primary]
1 x intel NUC with SSD [secondary]
1 x i5960 with SSD [arbiter]
.NET application using the C# driver (2.2).
Scenario 1 - No replica set:
My application running on a separate box connects to the primary (with no replica set configured) and has a total throughput of X.
Scenario 2 - 1 node replica set (on the primary):
Same two boxes as above, but mongod on the primary is started with --replSet. Total throughput is X - 15%. This makes sense as there is extra CPU and disk IO required.
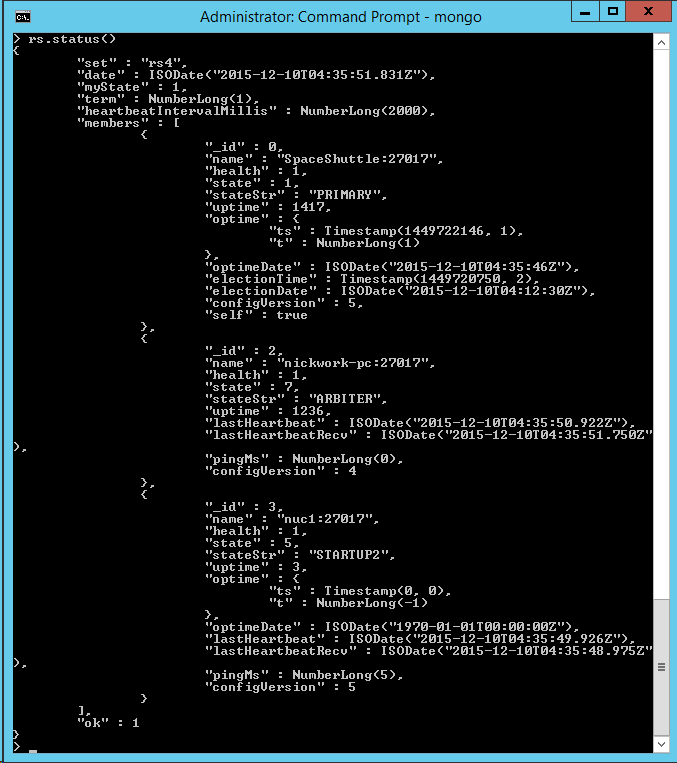
Scenario 3 - 2 node replica with arbiter:
This time I've configured a standard replica set. Throughput drops to X - 55%.
I can see the NUC (which is very weak) is CPU-bound, and the other two boxes are barely breaking a sweat. My understanding was that replication was asynchronous and that the replication from primary to secondary would not/should not slow down writing to the primary (at least not by such a large amount). As best I can tell I don't have the write concern set to majority (unless that is the default for a cluster).
I noticed that on my primary I was using zlib compression for both journal and collection (primary has a smaller SSD) and was using snappy for the replica.
I tried using snappy on both and performance jumped up more than expected, and CPU on the primary popped up to 100%.
I also tried zlib on both primary and secondary, and this showed better performance that mixed.