-
Type:
Bug
-
Resolution: Duplicate
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: 3.2.4, 3.2.5, 3.2.6
-
Component/s: WiredTiger
-
None
-
ALL
-
-
None
-
None
-
None
-
None
-
None
-
None
-
None
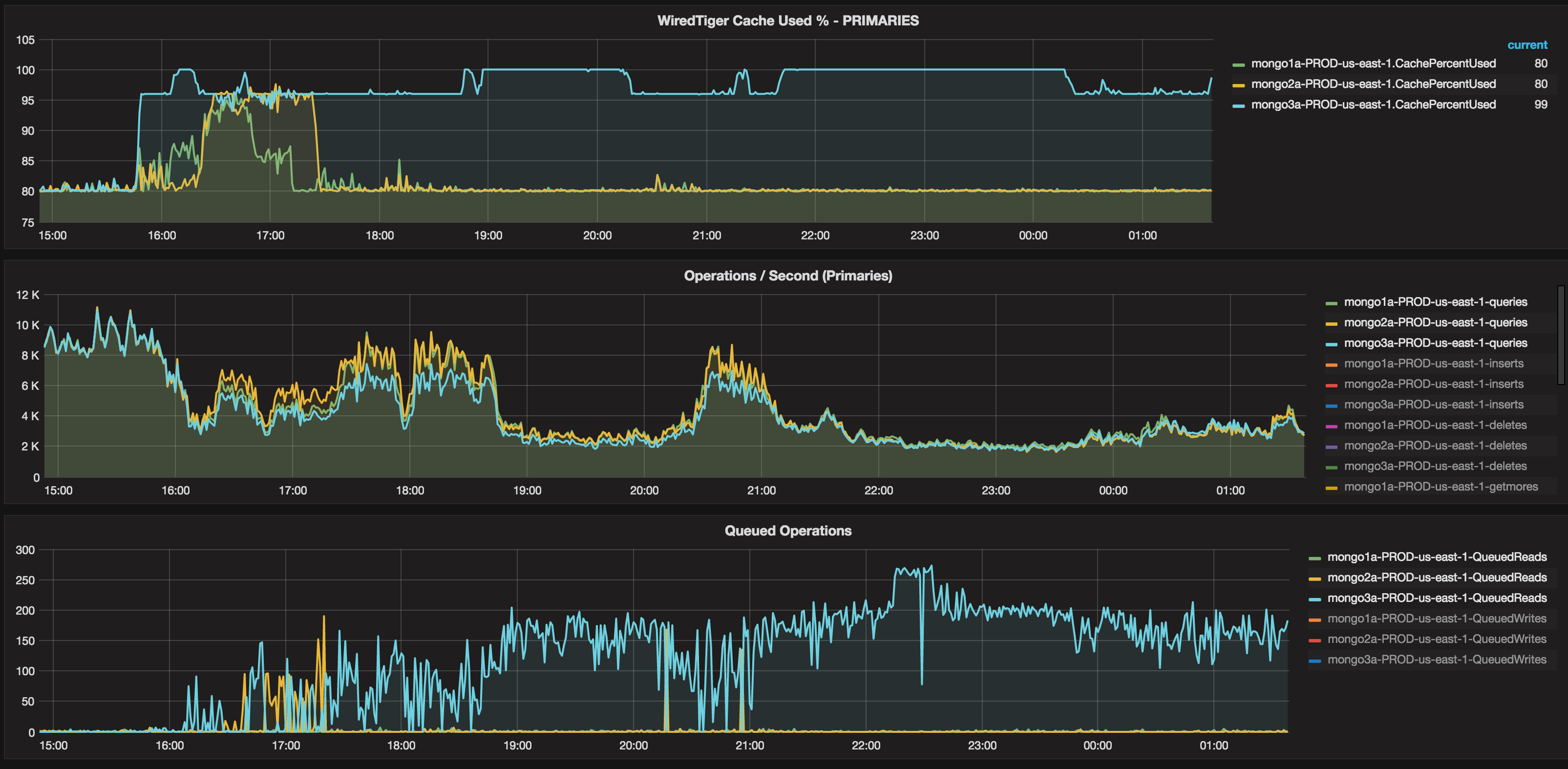
We have found that the last 3 releases of mongod can get into a state whereby the server is unable to service read tickets in anything like a timely manner. We find this occurring when the primary shard is under heavy read and write load. Once the server is in this state (%cache used ~=96%, %cache dirty ~> 30, read tickets available ~>60) for more than ~15 minutes it will remain in that state for up to an hour even when query load is significantly reduced (reduced to ~1/3 of previous load).
Checking tps and cpu load with iostat I see that the tps load is very low (usually under 1000 on ephemeral SSD storage) but cpu load is very high (usually 85% with system use taking anywhere between 15 and 50% of cpu load).
Looking in the logs for long-running queries or heavy query loads when in this condition shows no document scans. Checking db.currentOp() can return over 200 operations outstanding but no operations with secs_running>1.
We are running a 3.2.6 sharded cluster on ec2. The ami id is amzn-ami-hvm-2015.03.0.x86_64-gp2 (ami-1ecae776). Instance type is i2.xLarge. No other services are running on the server.
{kind=link}
- duplicates
-
SERVER-24580 Improve performance when WiredTiger cache is full
-

- Closed
-