-
Type:
Bug
-
Resolution: Unresolved
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: 3.0.12
-
Component/s: None
-
Query Execution
-
ALL
-
QE 2022-10-17, QE 2022-10-31, QE 2022-11-14, QE 2022-11-28, QE 2022-12-12, QE 2022-12-26, QE 2023-01-09
-
(copied to CRM)
-
None
-
3
-
None
-
None
-
None
-
None
-
None
-
None
Each of the stages listed in the title keeps a set of RecordIds; these are used to identify seen documents in order to ensure that we do not return the same document twice to the user. However, this requires memory proportional to the number of documents processed, and nothing is in place to ensure that we do not consume too much. One example of how to reproduce this unbounded memory growth is given below.
- 40 M documents of the form {x:0, y:0}
- index on {y:1}
- query of the following form (full repro script attached)
q = {$or: [{x: 0, y: 0}, {x: 0, y: 0}]}
db.c.find(q).hint({y: 1}).sort({z: -1}).limit(30).itcount()
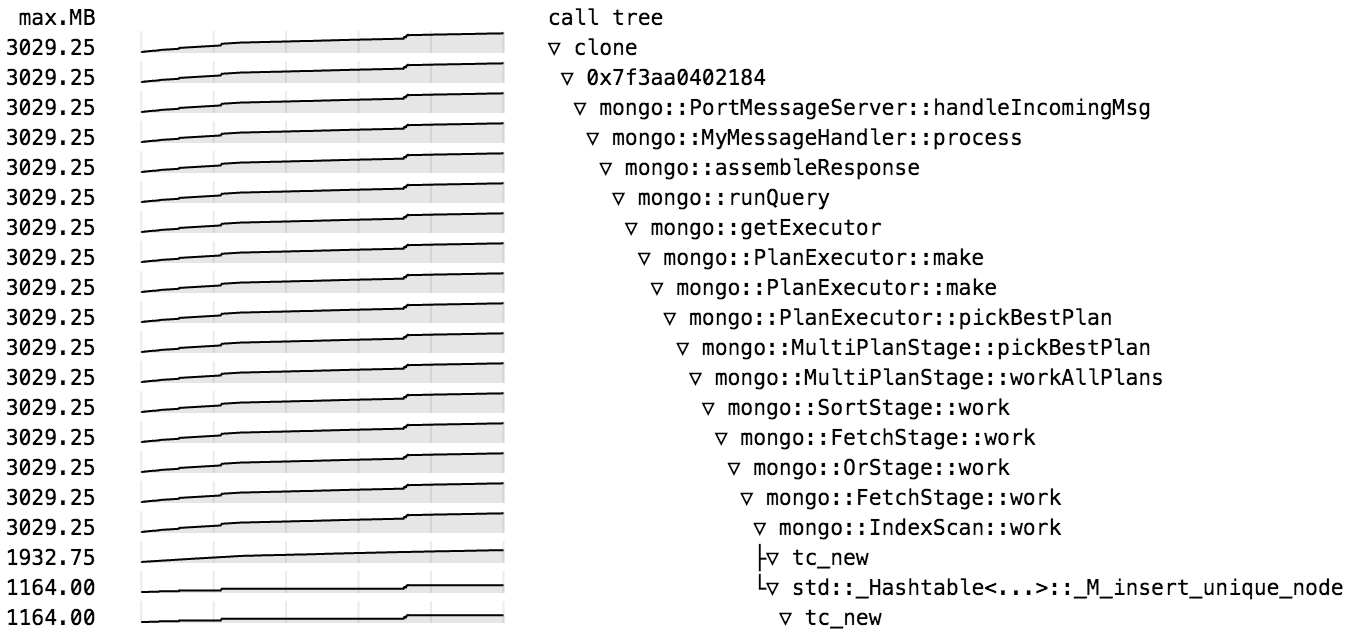
Heap profile call tree shows memory usage by OrStage::work grow to about 1.5 GB as it scans the collection, then drop back to 0 at conclusion of query. Graph in each row shows memory usage for that node and its descendants; second number in each row is max memory in MB for that node.


- depends on
-
SERVER-97745 OrStage should spill if allowDiskUse is specified and memory usage has exceeded some limit
-
- Blocked
-
-
-
- Blocked
-
-
-
- Blocked
-
- is duplicated by
-
-
- Closed
-
-
SERVER-123 multi-key _id deduping uses a lot of memory
-
- Closed
-
- is related to
-
-
- Backlog
-
- related to
-
-
- Open
-
-
SERVER-87134 Consider using roaring bitmaps for RecordId deduplication in IndexScan stages
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-