-
Type:
Bug
-
Resolution: Done
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: 3.2.11
-
Component/s: WiredTiger
-
None
-
Environment:MongoDB 3.2.11 with WiredTiger on FreeBSD 11.
Sharded Cluster
-shard 1 with 2 node in the replica set
-shard 2 with 1 node in the replica set
-
Fully Compatible
Hello,
We are currently benchmarking our workload against the following test environment:
- MongoDB 3.2.11
- Sharded Cluster (2 shards with 1 or 2 nodes in the replica set)
- Each node has 2x20 core CPUs and 32GB of memory
Our synthetic workload consists of:
- 450 threads doing an insert, waiting for 1 to 100ms and then updating the same document querying by the _id.
- We are using 2 mongos.
- We uses mgo golang driver, which appears to skew connections to one of the two mongos.
- We have also included our workload benchmarks in the upload.
We routinely see database operations drop from around 12000/s to 0 ops/s for several seconds at a time during what we believe to be WT cache eviction. After tuning the number of WT evictions threads to 8, eviction trigger(70), eviction target(68), eviction_dirty_trigger(20), eviction_dirty_target(18), we get a far more stable throughput of ~4000 ops/s with drops to 0 ops/s for only a second or so.
During the drops to 0 ops/s, we see no disk IO (we're using ZFS with a 1GB L2 cache, no L2ARC, verified with iostat) and we become CPU bound.
We are fully aware that we are pushing the system really hard but we didn't expect this behaviour during cache eviction. This issue does not occur when we are only running 200 worker threads against the system.
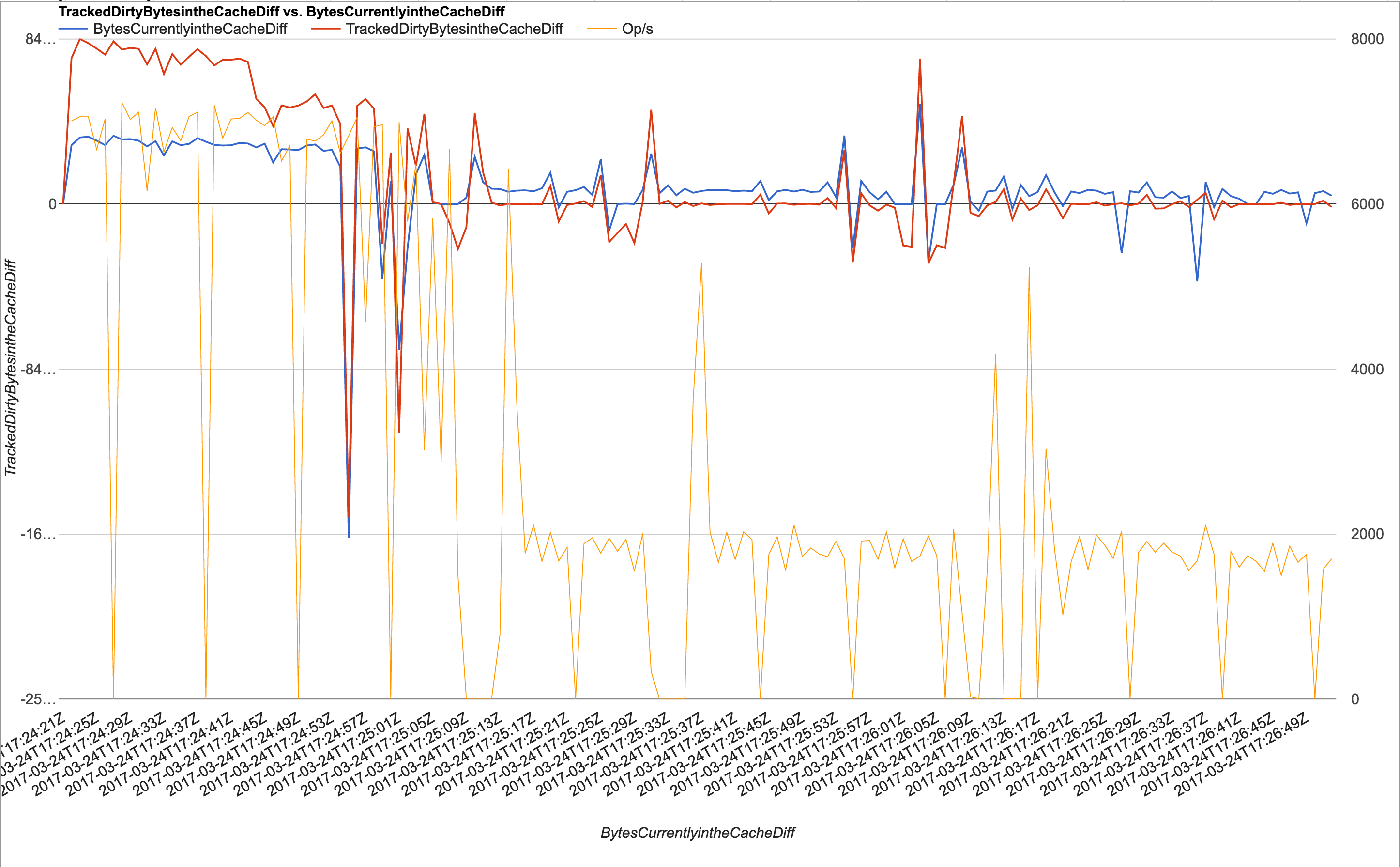
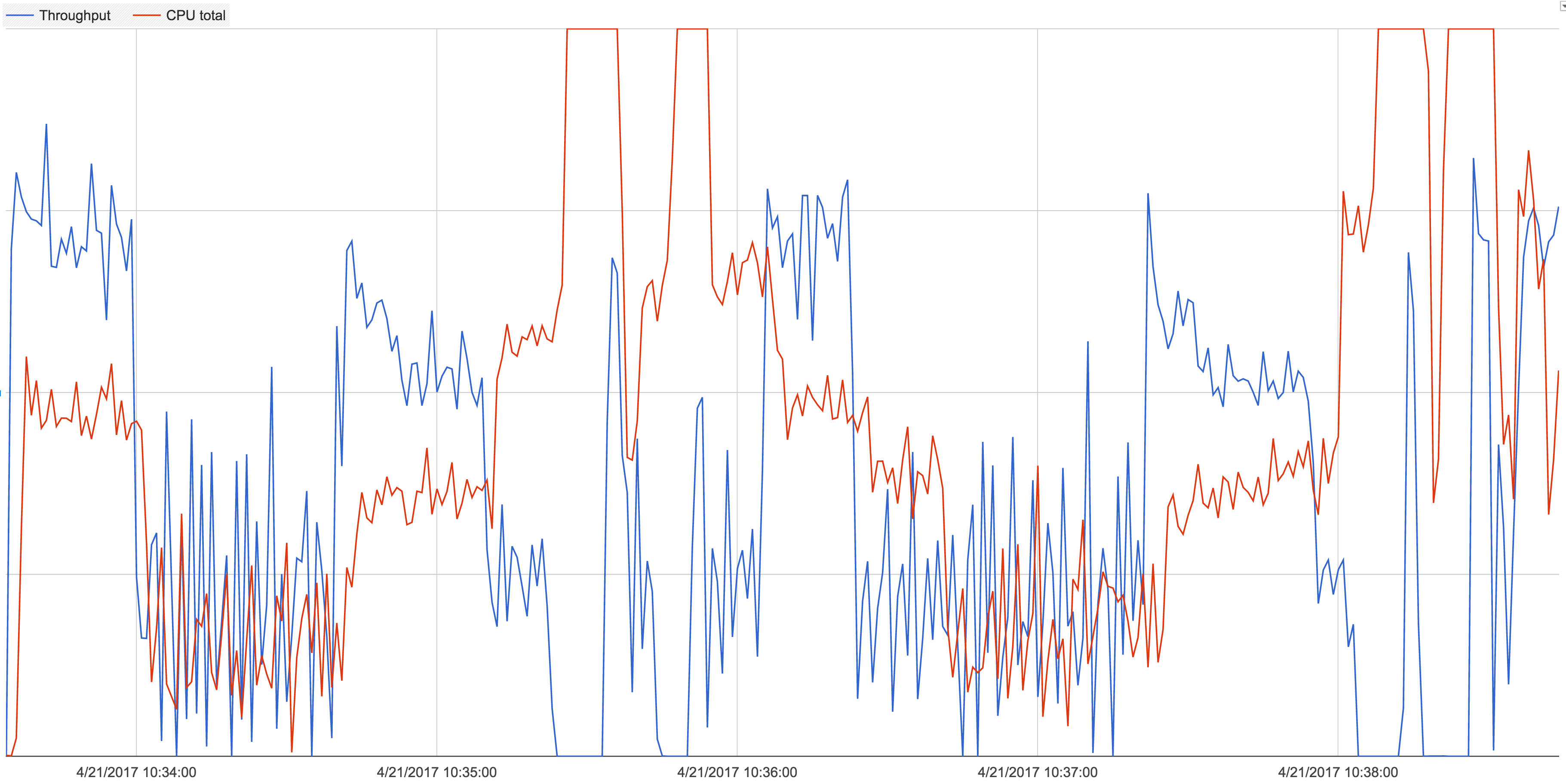
- duplicates
-
-
- Closed
-