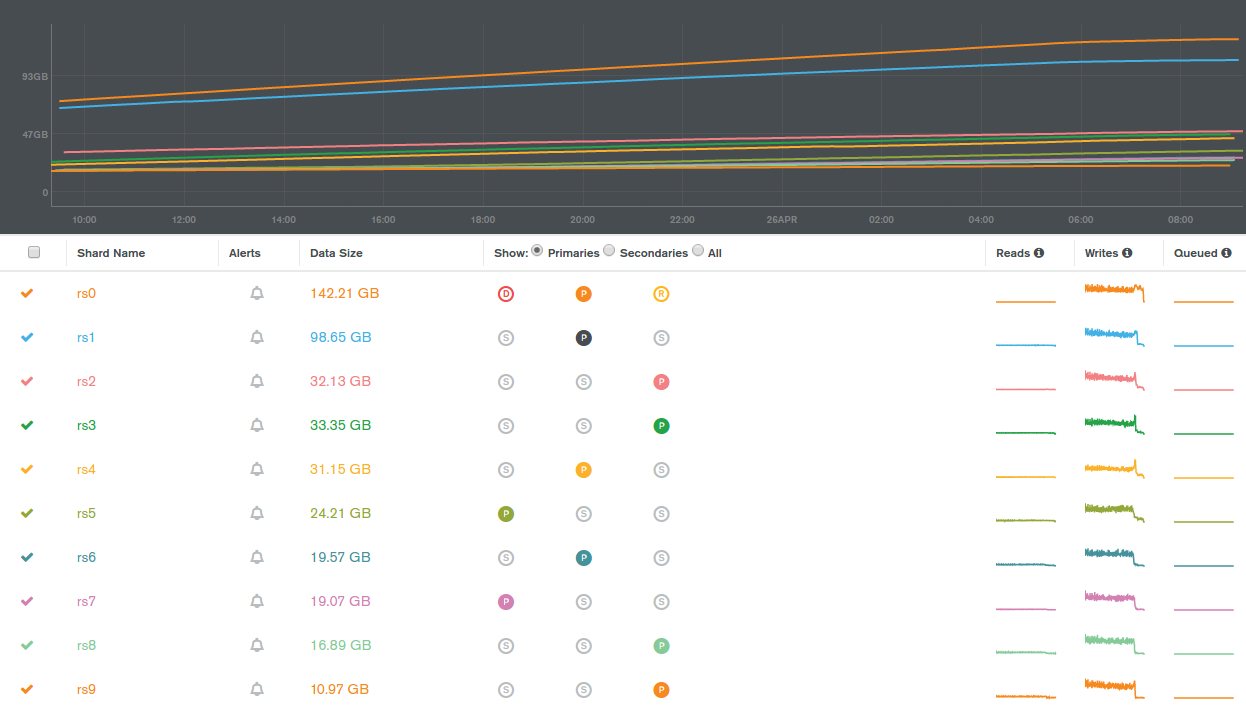
When dealing with multiple collections and sharding the default mongo balancer behavior seems to pick the next shard to move to in alphabetic order. Long term for big data this behavior is terrible for cluster balancing as the majority of data tends to get dropped on rs0, then rs1, then rs2, etc.
In my test scenario, I have 10 databases each with there primary set specifically to one of the shards below. Each database has 1000 collections, as I went from 0 documents to 10+ billion chunk distribution across those shards did this with the default balancer behavior. For performance reasons on mongo I could not use a single collection as performance was 100x worse. Range scans on an index performed horribly compared to full collection scans on small collections due to random IO versus sequential IO.
mongos> db.chunks.aggregate([ { $group:{ _id: "$shard", cnt: { $sum: 1} } }, {$sort: {"_id": 1}} ]);
{ "_id" : "rs0", "cnt" : 28128 }
{ "_id" : "rs1", "cnt" : 18092 }
{ "_id" : "rs2", "cnt" : 7748 }
{ "_id" : "rs3", "cnt" : 6475 }
{ "_id" : "rs4", "cnt" : 5429 }
{ "_id" : "rs5", "cnt" : 4412 }
{ "_id" : "rs6", "cnt" : 4185 }
{ "_id" : "rs7", "cnt" : 3956 }
{ "_id" : "rs8", "cnt" : 3640 }
{ "_id" : "rs9", "cnt" : 3012 }
mongos> db.version();
3.4.2
I'm at a point were I'm going to have to turn off the default mongo balancer and essentially write my own to get data distributed properly. I would like the balancer to be data storage aware when picking a shard to move to rather then picking them in alphabetic order. Random would even be better as that would produce a better data distribution then what is currently occurring.