-
Type:
Bug
-
Resolution: Gone away
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: 3.2.12
-
Component/s: None
-
None
-
ALL
We experienced the following on our production replica set: 3 secondaries 1 primary, MongoDB 3.2.12 + WiredTiger.
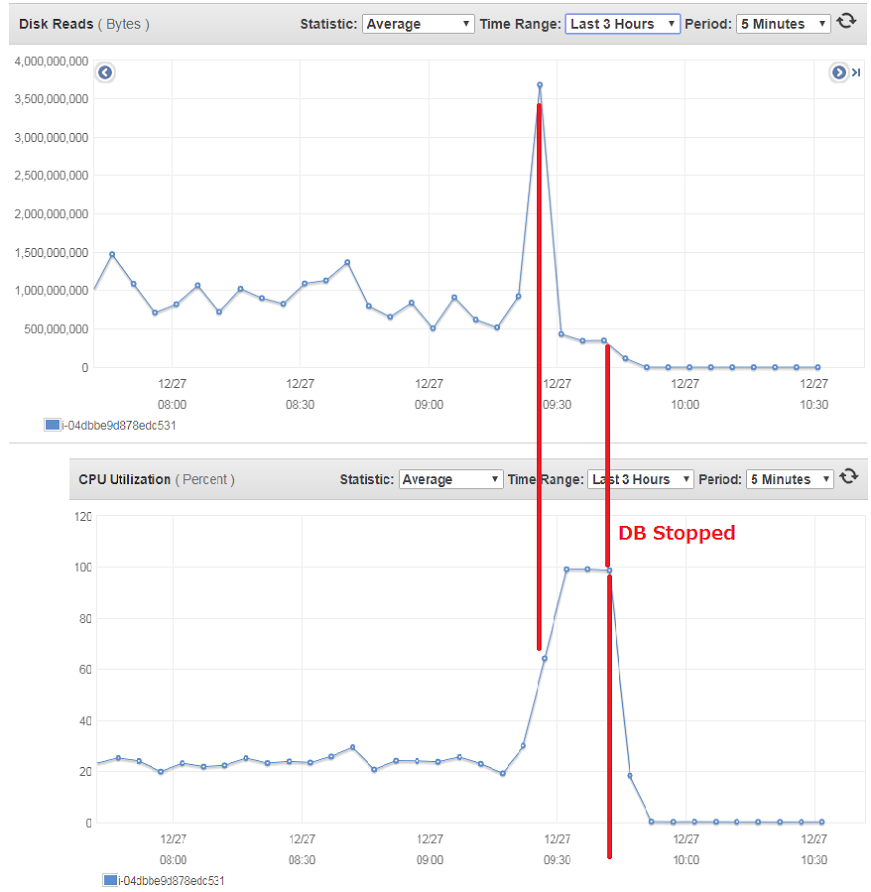
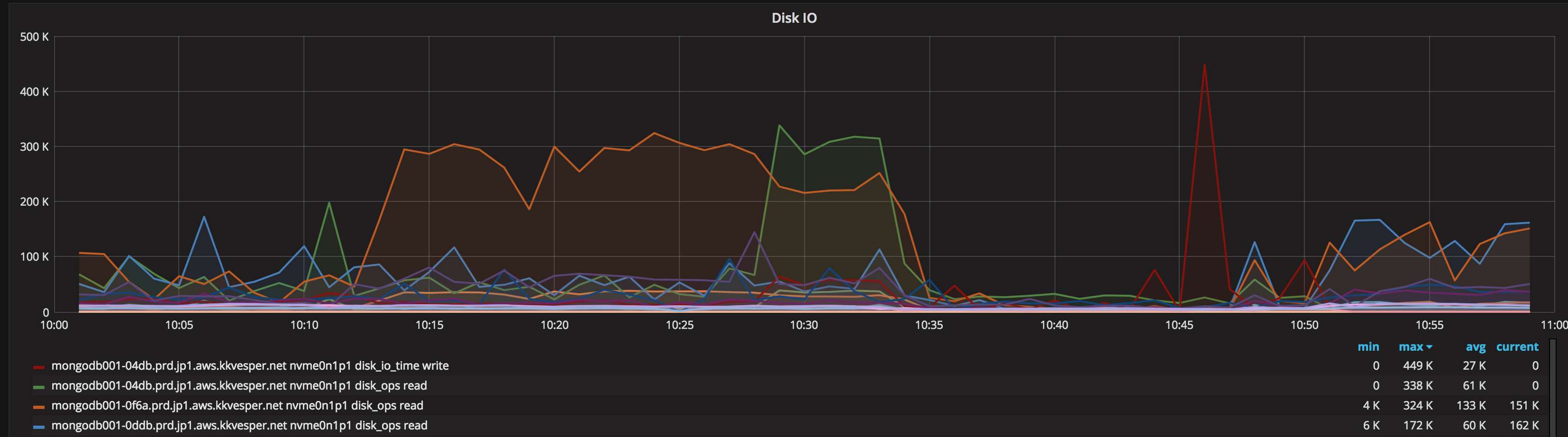
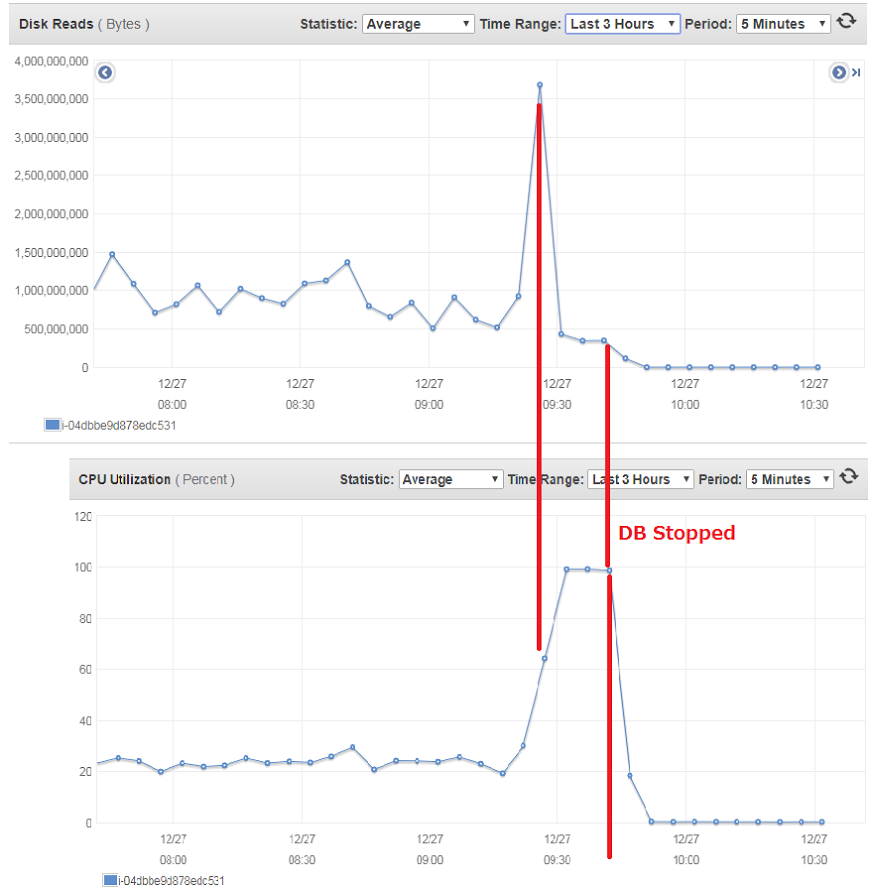
1. All secondaries saw a spike in disk usage (about 4-5x base load, we see something like this about twice per day randomly)
2. One of the secondary's mongod CPU usage shot up to 100%. At this time the replica set continued to route queries to the affected instance, but the instance did not process them.
3. We killed all queries on the affected instance via console, the CPU remained at 100% it continued to NOT process queries.
4. Finally we removed the affected process from the replica set and again we could process all queries.
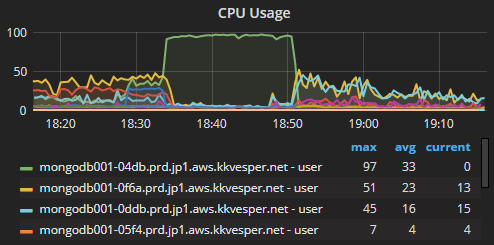
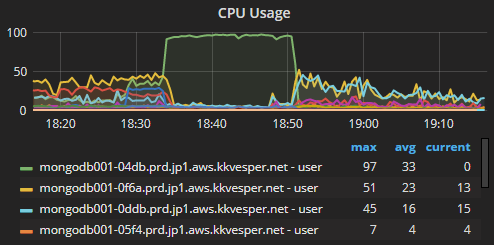
Here is a CPU chart of the 4 instances. As you can see CPU of one of the instances hit 100%. (As it was not responding to queries, our app failed and stopped sending new queries, so other instances went to low CPU)
Here is a chart showing the disk usage spike on the affected instance which happened before the high CPU.
Unfortunately we did not get a core dump of the affected process.