-
Type:
Bug
-
Resolution: Duplicate
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: 3.6.1
-
Component/s: WiredTiger
-
ALL
-
None
-
None
-
None
-
None
-
None
-
None
-
None
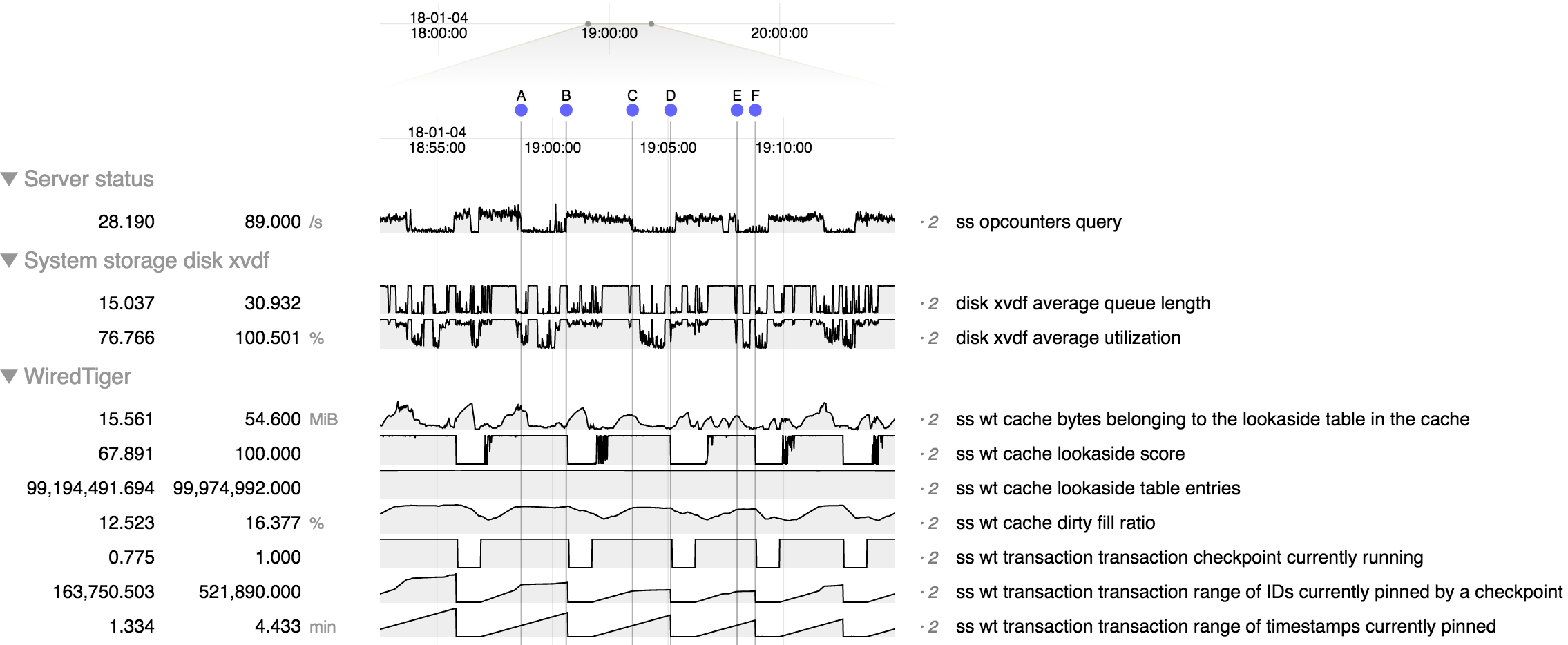
We are having an issue where mongo becomes unresponsive for minutes at a time. During this period it is emptying the dirty cache.
The pattern we are seeing is that during normal operation performance is generally acceptable. However we have a large amount of data we want to delete from the cluster and starting that deletion process triggers the stalling behavior. Once this behavior starts it seems to reappear even after we've stopped the deletions. Restarting the server processes causes the problem to go away until we start the deletions again.
I'm uncertain if this is related but we previously had an issue (SERVER-31141) with stalls when the disk cache reached the 95% threshold but WT-3079 appeared to fix that issue.
I have logs and diagnostic data I can add to the upload portal.
Let me know if any other information would be helpful.
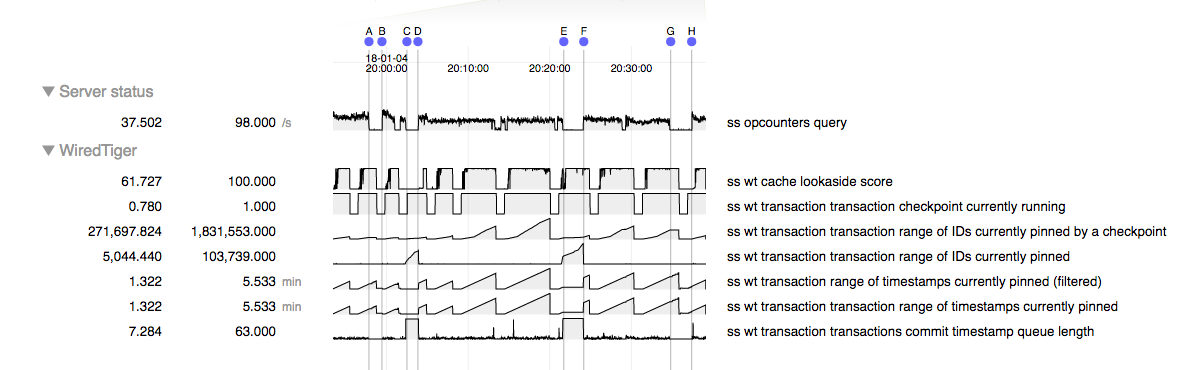
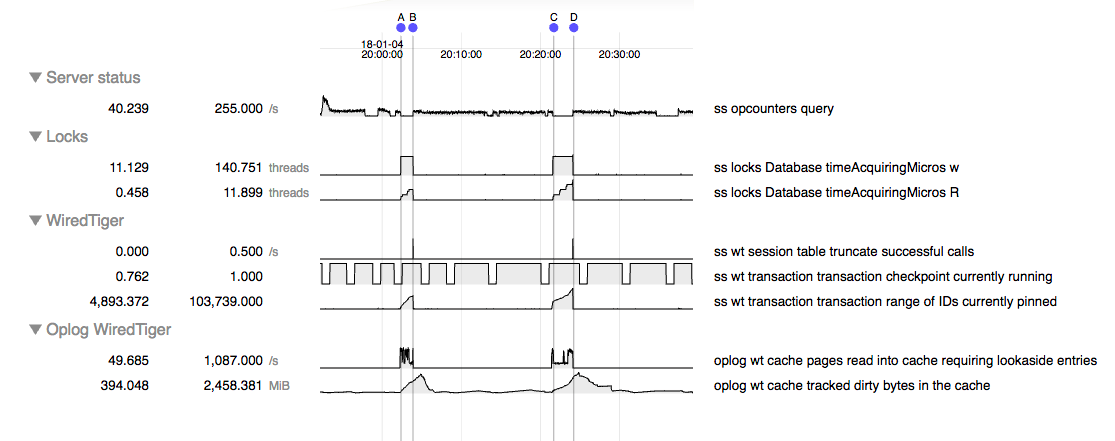
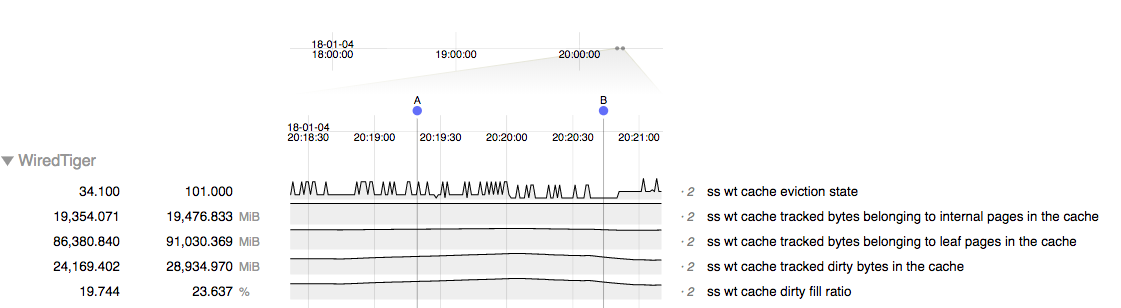
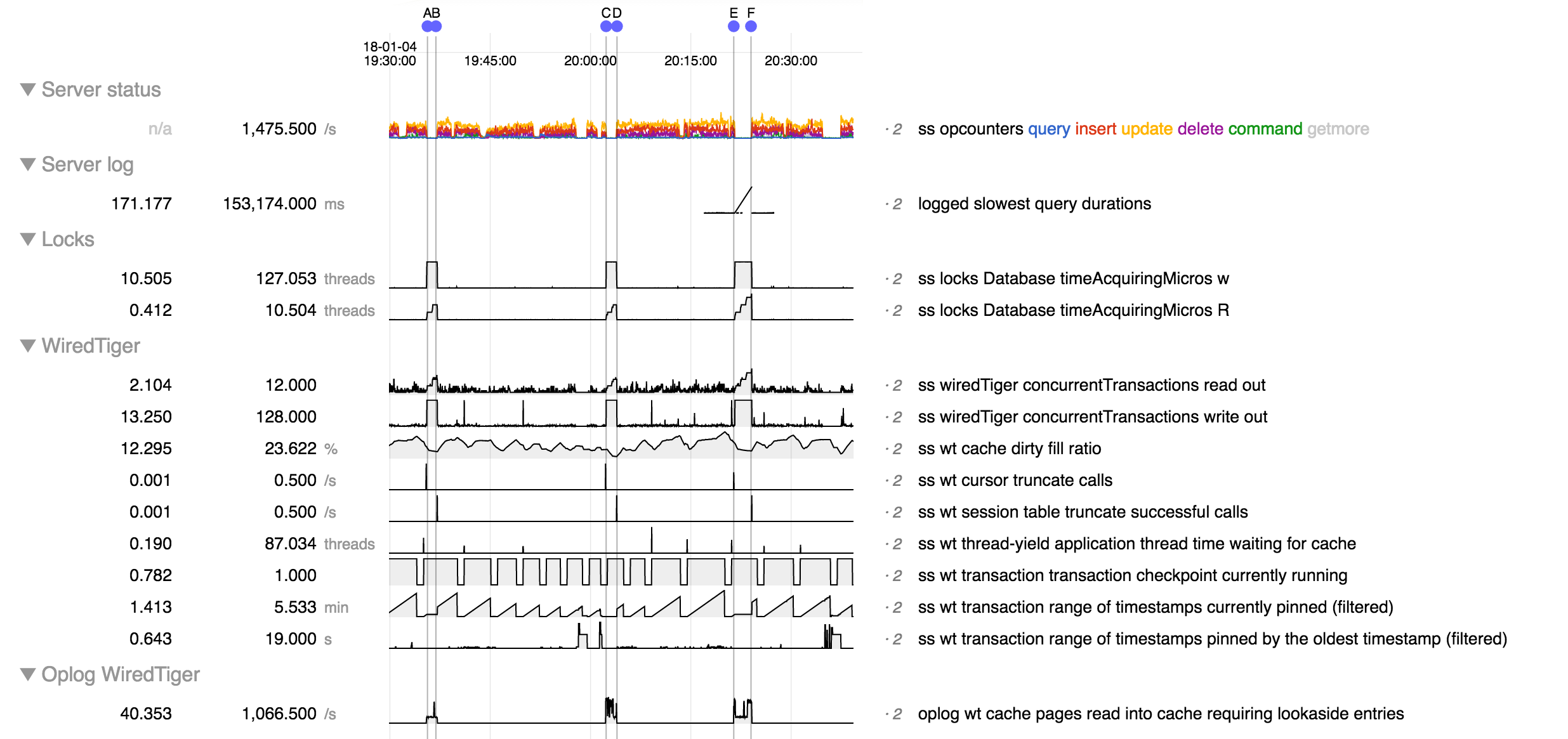
- duplicates
-
-
- Closed
-
- related to
-
WT-3766 Lookaside sweep for obsolete updates
-
- Closed
-