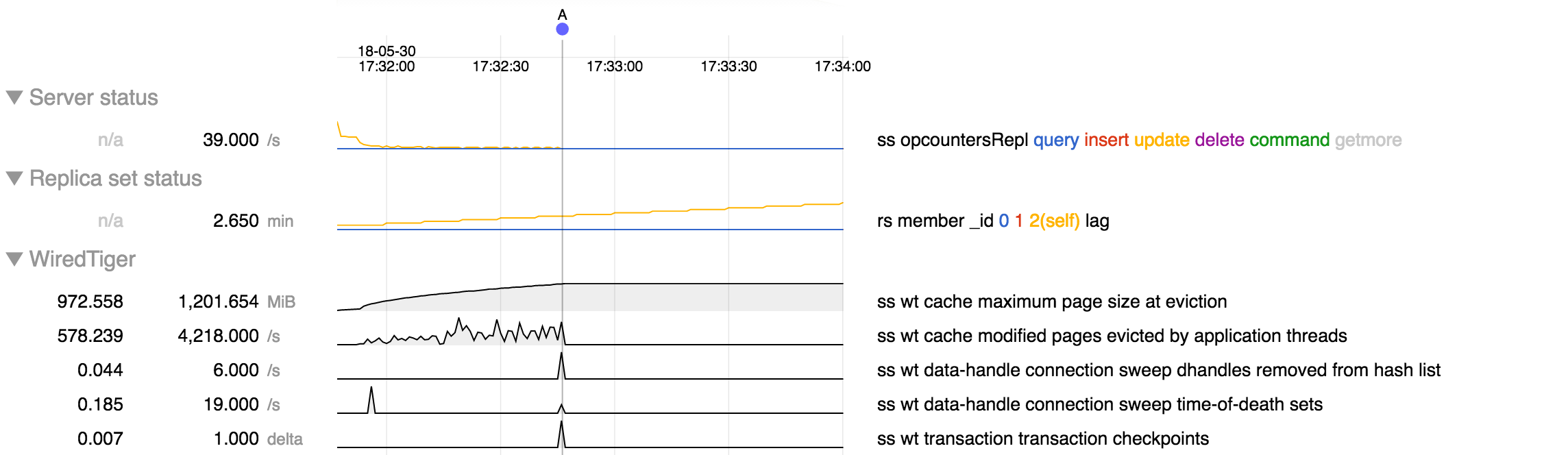
We have seen a couple of cases in the field where under heavy cache pressure a node can get stuck with the WT cache full. In the cases seen so far the cache pressure has been due to replica set lag, which causes the majority commit point to lag, creating cache pressure.
So far we don't have a reproducer and don't have FTDC data covering the inception of the issue (SERVER-32876) so this ticket for now is a placeholder to gather information.
- depends on
-
SERVER-32876 Don't stall ftdc due to WT cache full
-

- Closed
-
-
WT-4105 Optimize cache usage for update workload with history pinned
-

- Closed
-
- is related to
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
- related to
-
-
- Backlog
-
-
-
- Closed
-
-
-
- Closed
-
-
-

- Closed
-
-
SERVER-36373 create test to fill WT cache during steady state replication
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
- mentioned in
-
Page Loading...