-
Type:
Bug
-
Resolution: Duplicate
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: 3.6.5
-
Component/s: WiredTiger
-
ALL
-
-
None
-
None
-
None
-
None
-
None
-
None
-
None
Environment:
- 3 server replica sets on AWS (t2.medium) running 3.6.5.
- All writes employ MAJORITY write concern.
- Default journaling is enabled.
Expected behaviour:
That the supported recovery methods return the instance to health.
Observed Behaviour:
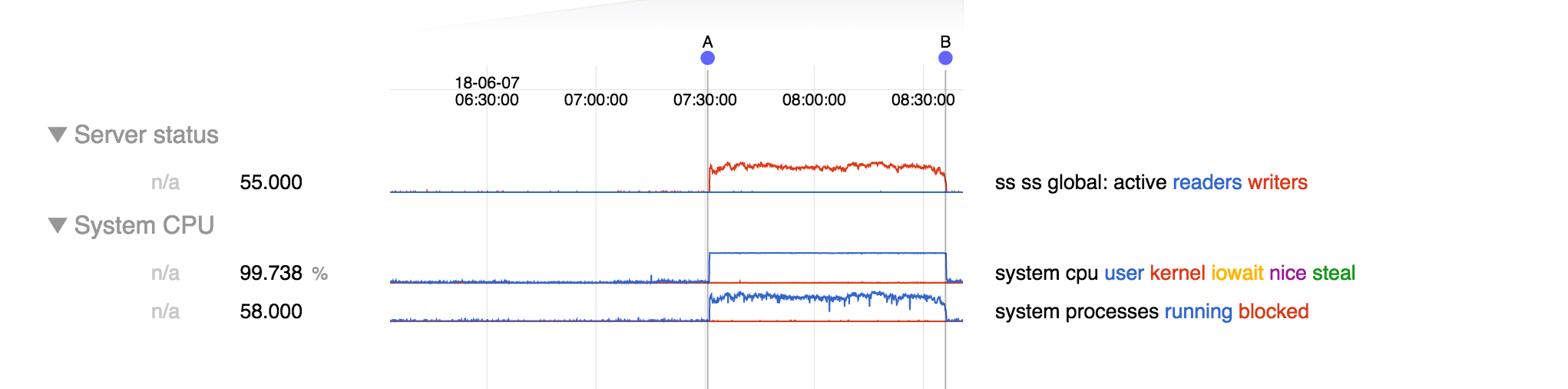
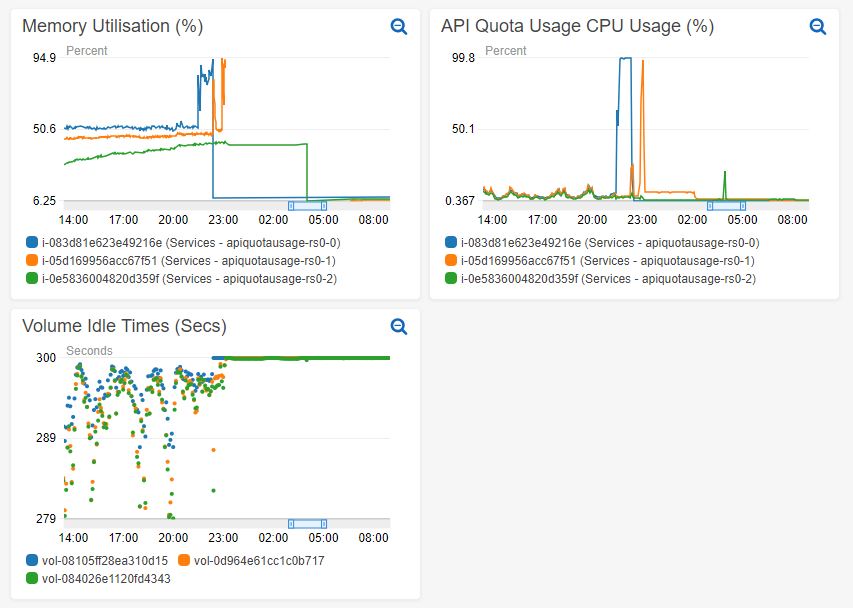
After an unclean shutdown a secondary never recovers on it's own, never making it past the final step in the following sample log, see log1.txt.
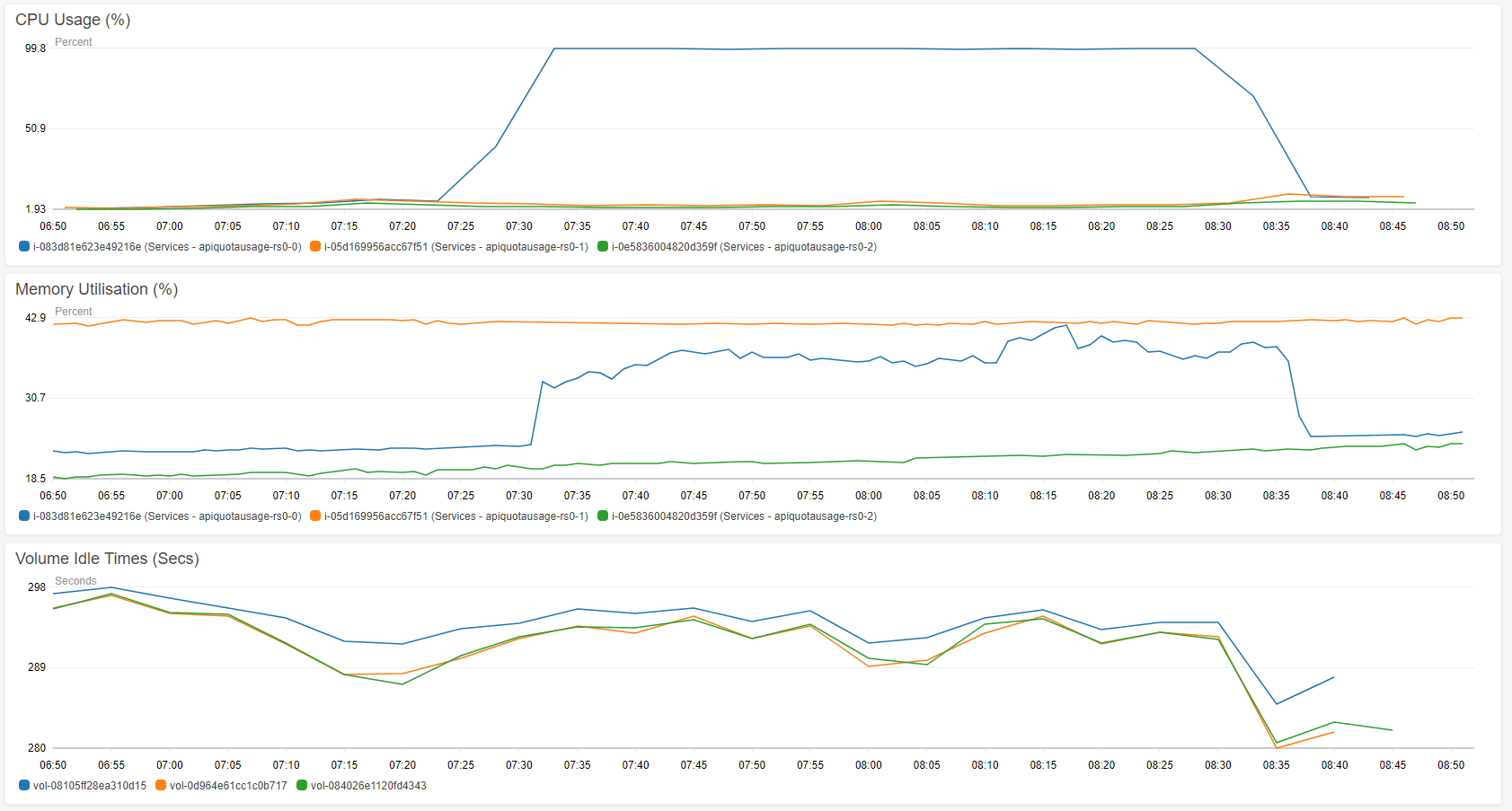
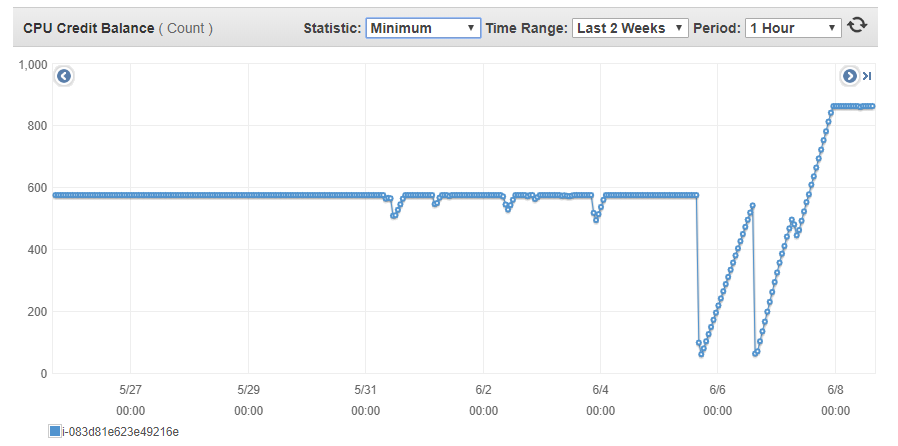
Clearly the instance had run out of disk space at this point (100GB provisioned for a database normally 1.6GB). Here are the contents of the /var/mongodata folder, see log2.txt.
So it appears the culprit is entirely the WiredTigerLAS.wt file.
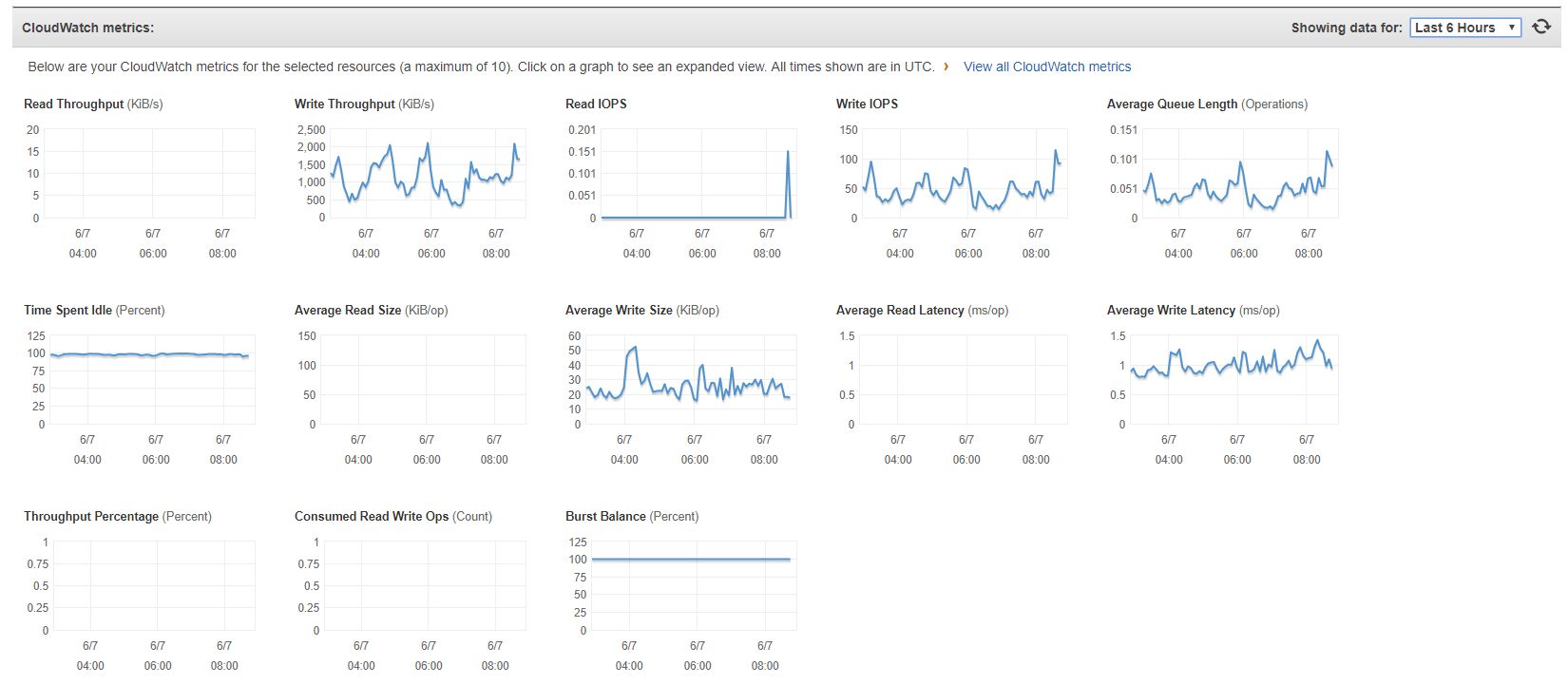
For additional information the df output at this point:
Filesystem Size Used Avail Use% Mounted on devtmpfs 7.9G 60K 7.9G 1% /dev tmpfs 7.9G 0 7.9G 0% /dev/shm /dev/xvda1 20G 2.8G 17G 14% / /dev/xvdi 100G 100G 140K 100% /var/mongodata
The only option to recover this instance is to do a full resync (after deleting the contents of /var/mongodata), see log3.txt.
The initial sync currently takes less than 60 seconds but this will obviously not be suitable once the size of the data set grows.
- duplicates
-
-
- Closed
-
-
-
- Closed
-
- is related to
-
-
- Closed
-