-
Type:
Bug
-
Resolution: Duplicate
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: 3.6.6, 3.6.12
-
Component/s: Performance, WiredTiger
-
None
-
Environment:Ubuntu 16.04.4 LTS, AWS i3.4xl hvm
-
ALL
-
-
None
-
None
-
None
-
None
-
None
-
None
-
None
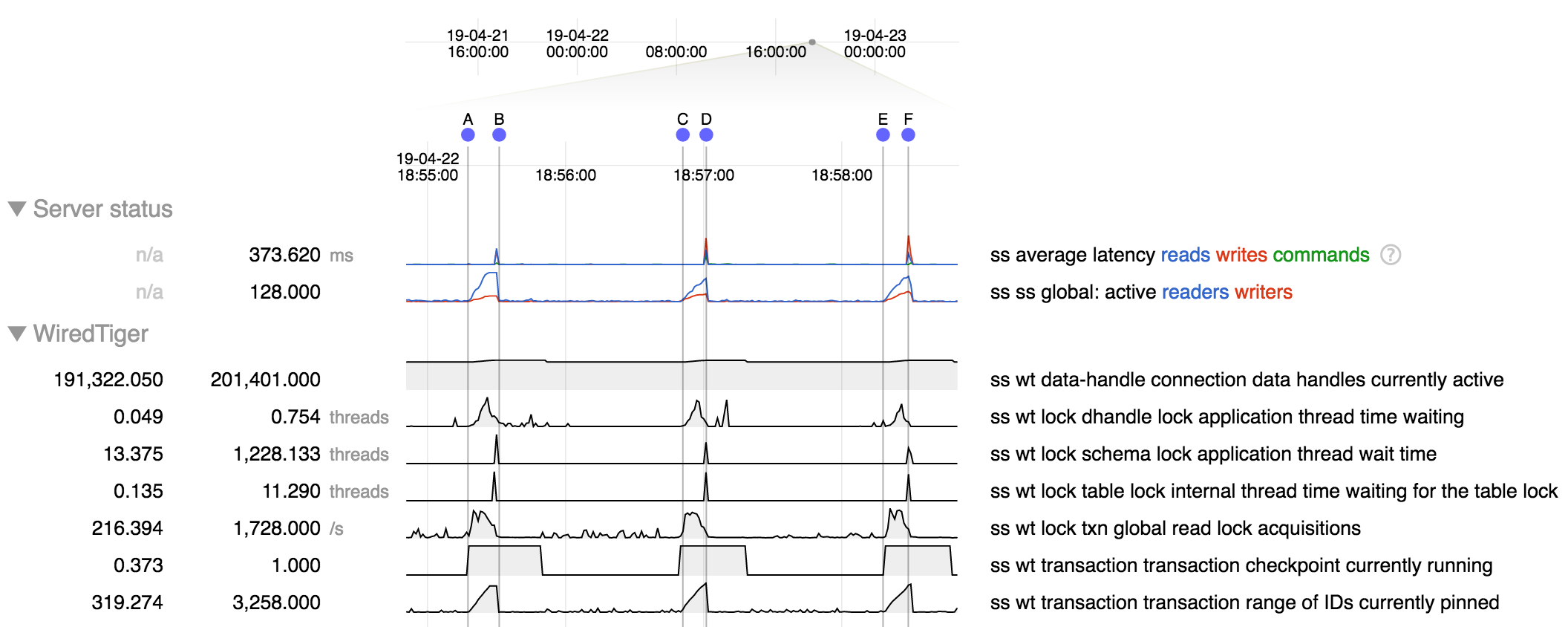
We are seeing very consistent degradation in our primary periodically in our mongo logs. Every 60-90s or so we see a large batch of queries that seemingly gets blocked by a global lock before resolving on the order of seconds. These queries are generally fully indexed queries, often by _id. They span across multiple databases and collections at the same time.
We originally noticed this consistently at 80s interval in 3.6.6, and since upgrading to 3.6.12 it is less prevalent, but still happening. In 3.6.12 we are seeing in vary in range from 60-90s generally.
We have approximately 150 databases, with approximately 150 collections in each one. We are running on an AWS i3.8xlarge HVM on Ubuntu 16 LTS.
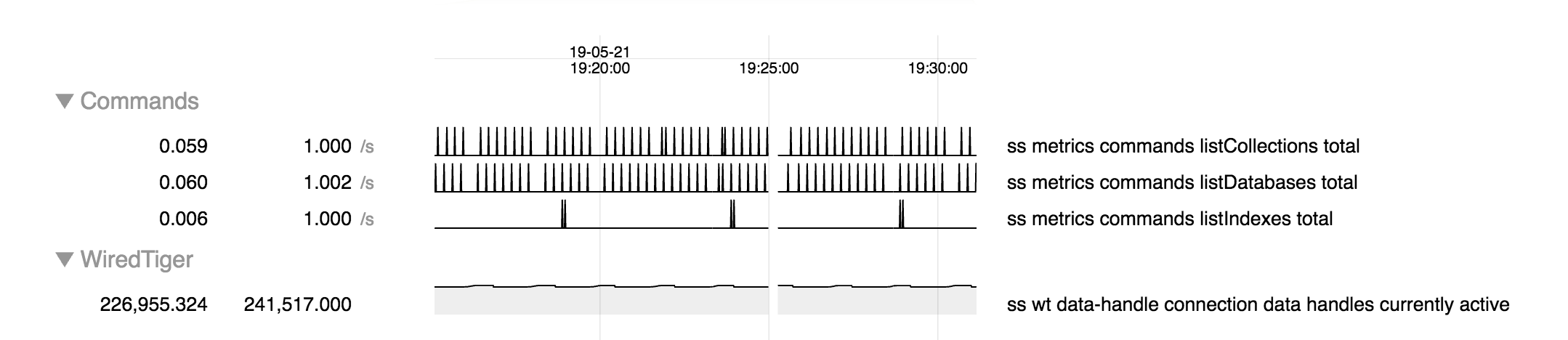
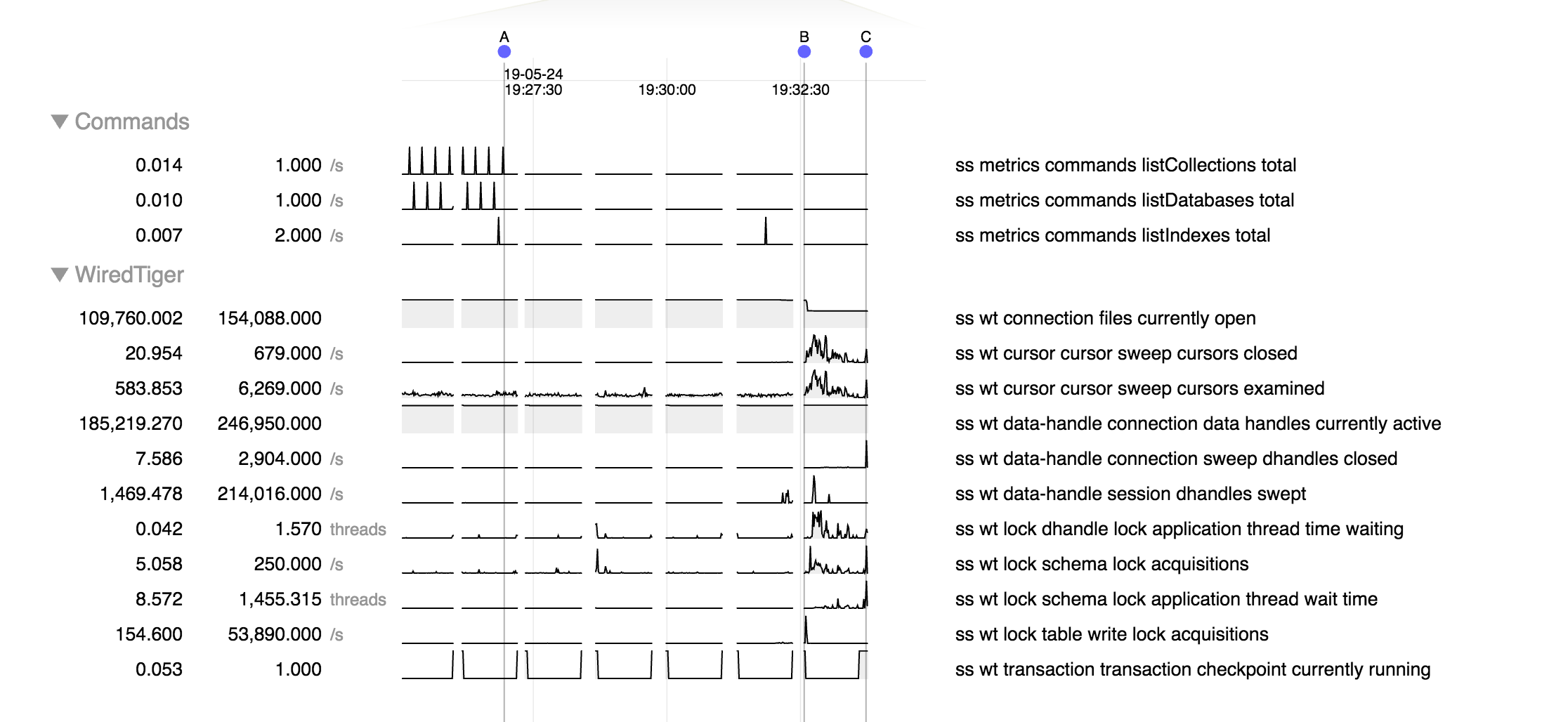
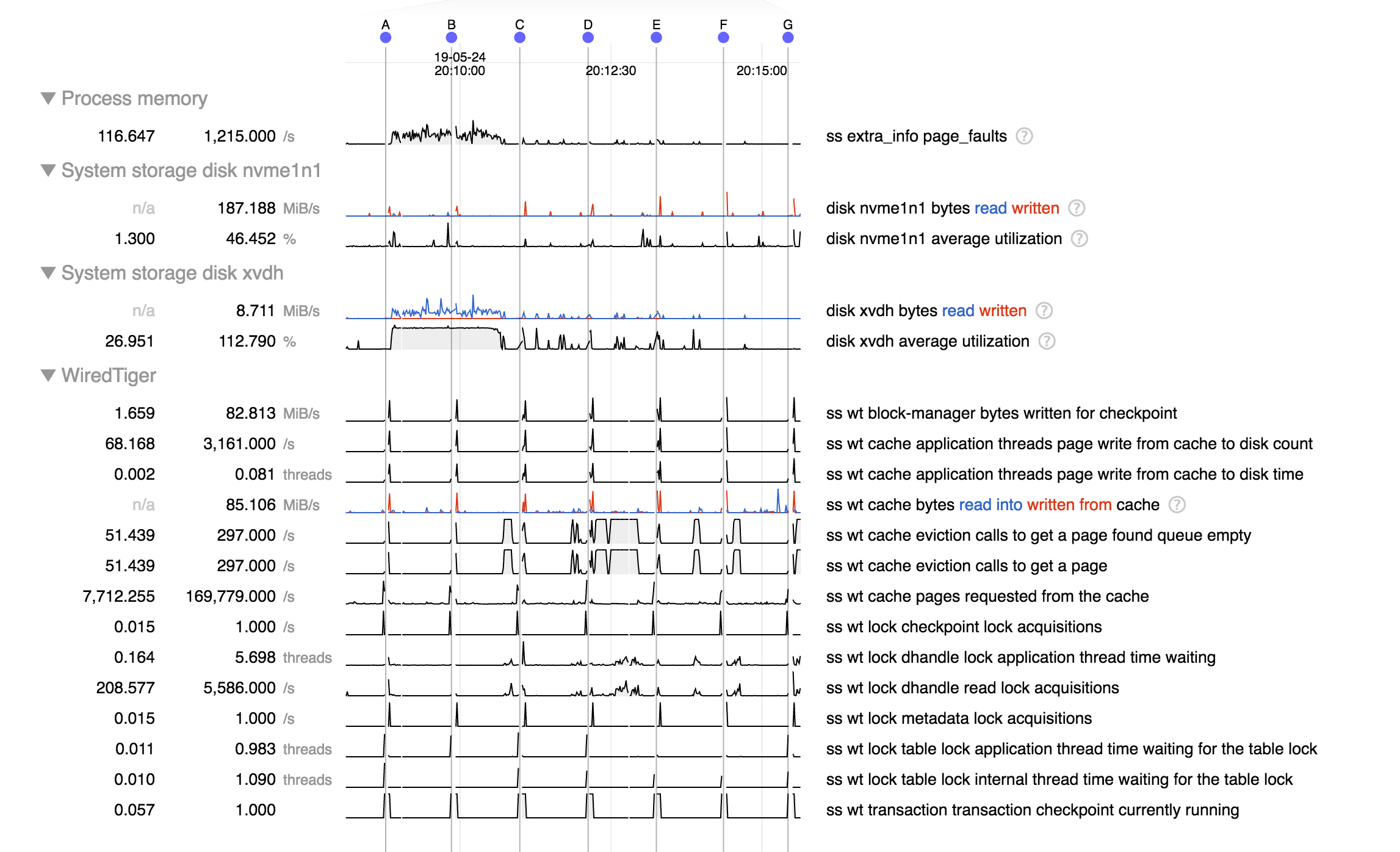
Here are a couple logs, one from each batch of failures that show redacted, operations that we believe should resolve quickly. I have the diagnostics directory for this time frame if you can provide a secure upload link.
2019-04-22T22:51:03.768+0000 I COMMAND [conn547794] command command: find { find: "files", filter: { : "" }, projection: { _meta: 0 }, limit: 1, singleBatch: true, batchSize: 1, returnKey: false, showRecordId: false, $clusterTime: { clusterTime: Timestamp(1555973455, 204), signature: { hash: BinData(0, 5CC075D6D06195ED6EBD7ABD18FDA15406AC89AD), keyId: 6644202815071715329 } }, lsid: { id: UUID("68954c85-d1f9-4d49-9ee9-0c6b2bf4d54a") }, $db: "" } planSummary: IXSCAN { url: 1 } keysExamined:1 docsExamined:1 cursorExhausted:1 numYields:0 nreturned:1 reslen:669 locks:{ Global: { acquireCount: { r: 2 } }, Database: { acquireCount: { r: 1 } }, Collection: { acquireCount: { r: 1 } } } protocol:op_query 8144ms
2019-04-22T22:52:31.966+0000 I COMMAND [conn542979] command command: find { find: "", filter: { _id: "" }, projection: { _meta: 0 }, limit: 1, singleBatch: true, batchSize: 1, returnKey: false, showRecordId: false, $clusterTime: { clusterTime: Timestamp(1555973546, 62), signature: { hash: BinData(0, F8034F377C49CFC559FBD6DC0B17F4112229E6F3), keyId: 6644202815071715329 } }, lsid: { id: UUID("ee45d554-bda5-42b7-883d-b8792f2c08aa") }, $db: "" } planSummary: IDHACK keysExamined:1 docsExamined:1 cursorExhausted:1 numYields:0 nreturned:1 reslen:376401 locks:{ Global: { acquireCount: { r: 2 } }, Database: { acquireCount: { r: 1 } }, Collection: { acquireCount: { r: 1 } } } protocol:op_query 5821ms
2019-04-22T22:54:02.859+0000 I WRITE [conn548157] update command: { q: { _id: "" }, u: { $set: { }, $setOnInsert: { }, $inc: { } }, multi: false, upsert: false } planSummary: IDHACK keysExamined:1 docsExamined:1 nMatched:1 nModified:1 keysInserted:1 keysDeleted:1 numYields:1 locks:{ Global: { acquireCount: { r: 3, w: 3 } }, Database: { acquireCount: { w: 3 }, acquireWaitCount: { w: 1 }, timeAcquiringMicros: { w: 3482747 } }, Collection: { acquireCount: { w: 2 } }, oplog: { acquireCount: { w: 1 } } } 3544ms
- related to
-
-
- Closed
-
-
WT-6421 Avoid parsing metadata checkpoint for clean files
-
- Closed
-