-
Type:
Bug
-
Resolution: Gone away
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: 4.2.0, 4.2.11
-
Component/s: None
-
None
-
ALL
-
-
Service Arch 2021-02-08, Service Arch 2021-02-22, Service Arch 2021-03-08, Service Arch 2021-03-22, Service Arch 2021-04-05, Service Arch 2021-04-19, Service Arch 2021-05-03
-
(copied to CRM)
-
None
-
3
-
None
-
None
-
None
-
None
-
None
-
None
Test consists of 500 threads doing secondaryPreferred reads as fast as possible against a single shard cluster. In the chart below the queries before A are from the primary for reference, after A are secondaryPreferred.
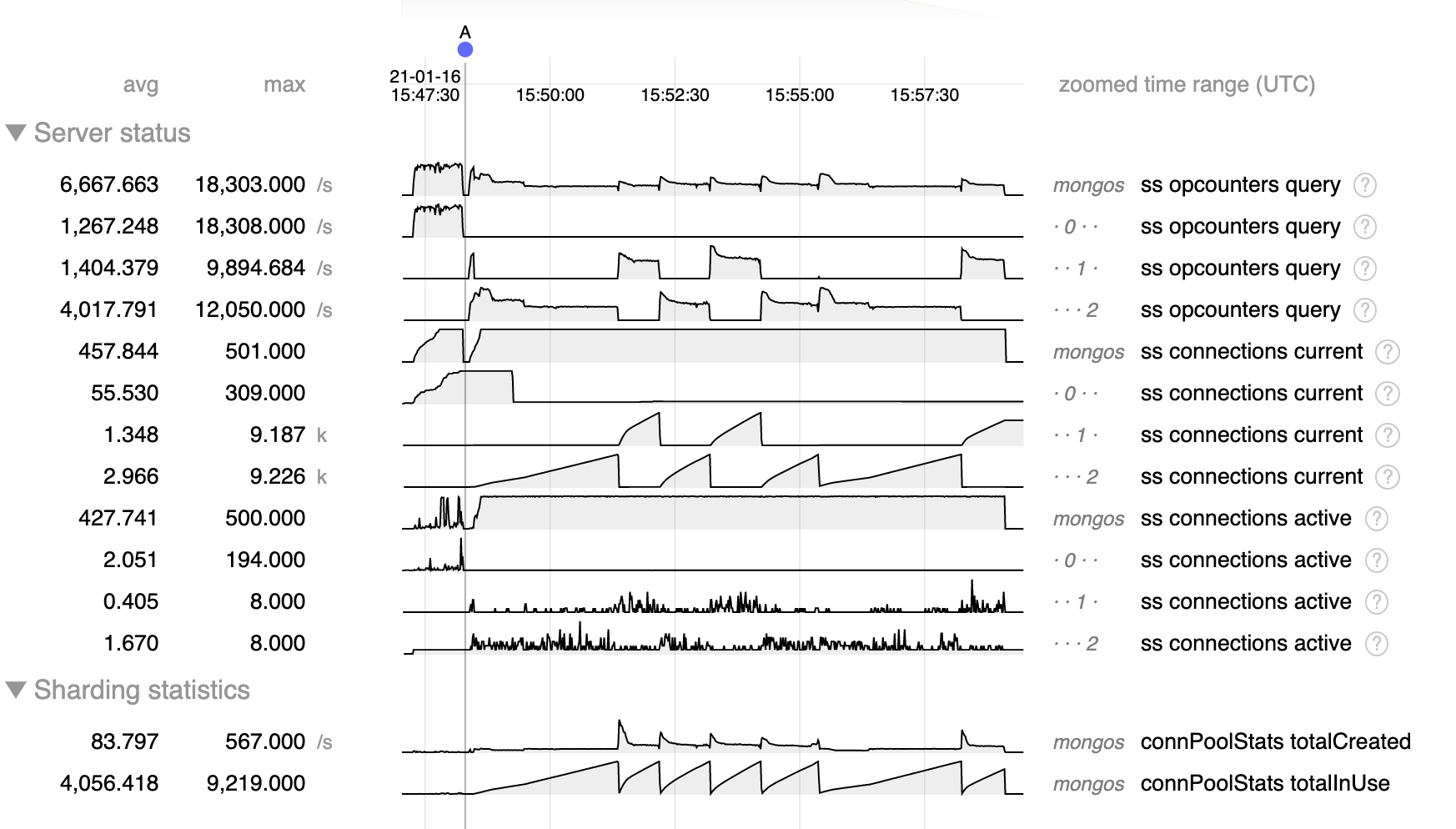
- As expected, there are 500 connections to mongos, so there are as many as 500 outstanding operations.
- Before A when reading from the primary (node 0) connections from mongos to mongod build to about 300, and the pool totalInUse and mongod active connections metrics are at times in the hundreds, justifying the need for 300 connections.
- But after A when doing secondary reads connections from mongos to mongod build steadily up to about 10 k connections, far more than the 500 possible outstanding operations. Most of those are considered "in use" by mongos, but very few are "active" in mongod.
- After reaching about 10 k connections the mongos seems to reset and begin building connections again, either to the same or a different secondary.
- Slow query logs from mongos record a large number of operations taking tens of milliseconds, but almost non on mongod. The latency metrics from mongod confirm that there is no performance bottleneck on mongod.
- Query throughput after A when doing secondary reads is much less than the primary reads before A. This seems to get worse as the number of connections build, but the latency on mongod remains low, so this is probably not due to an issue on mongod with the number of connections, but rather some issue in mongos.

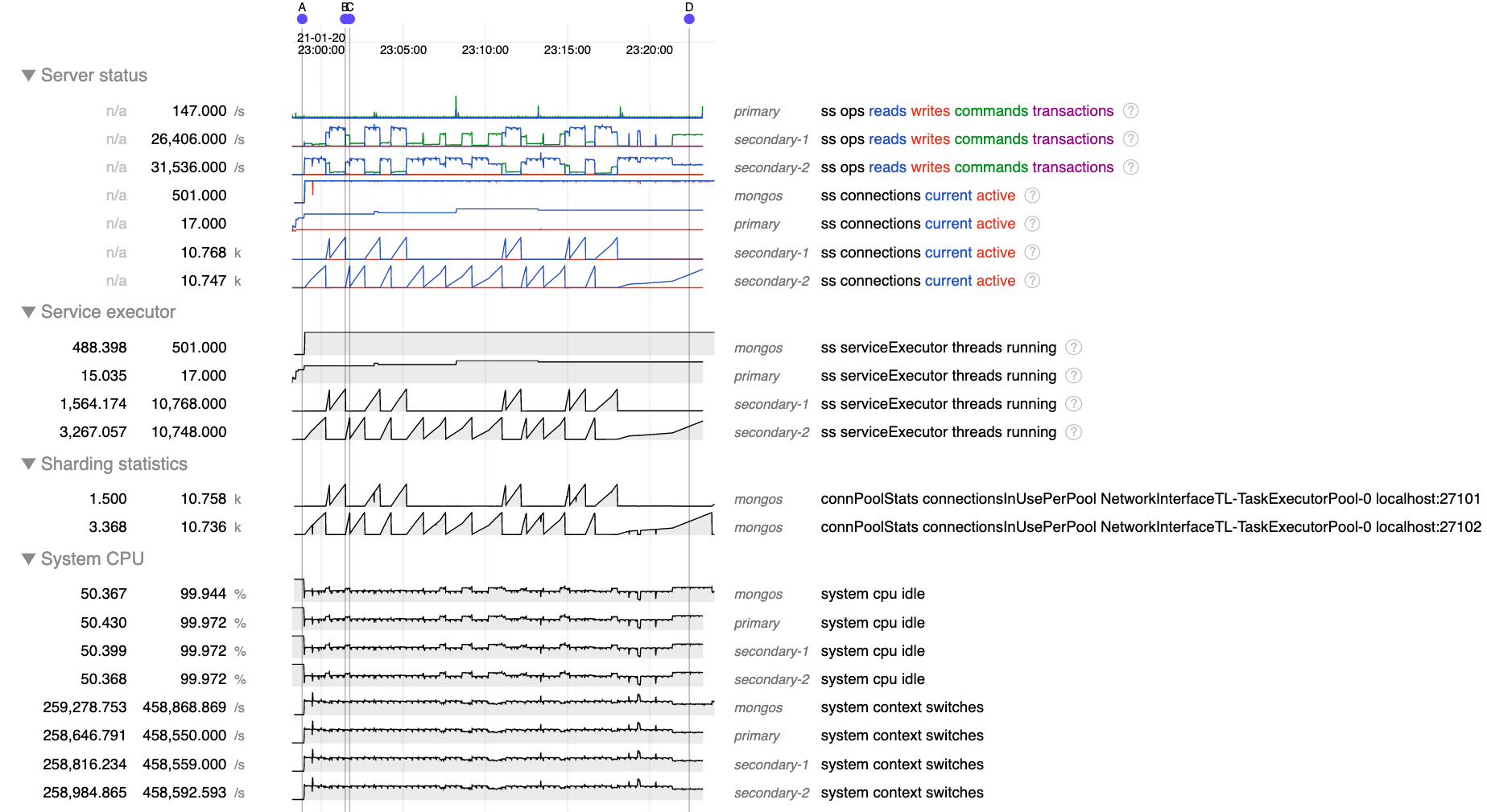


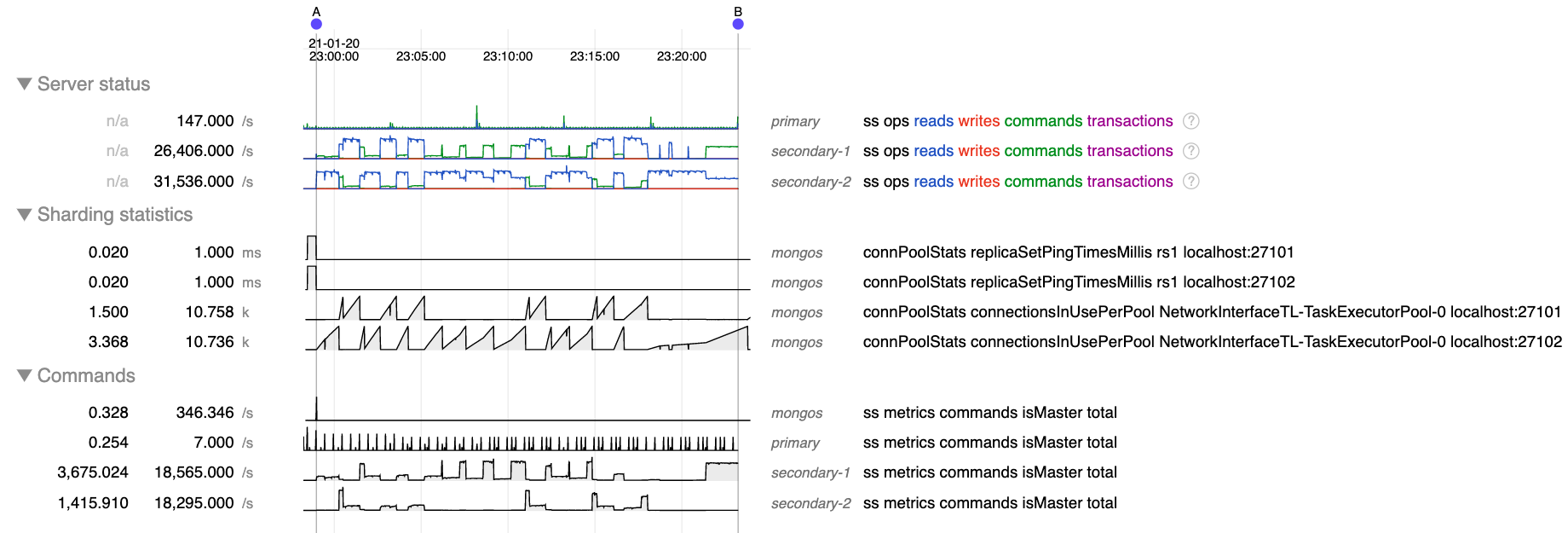

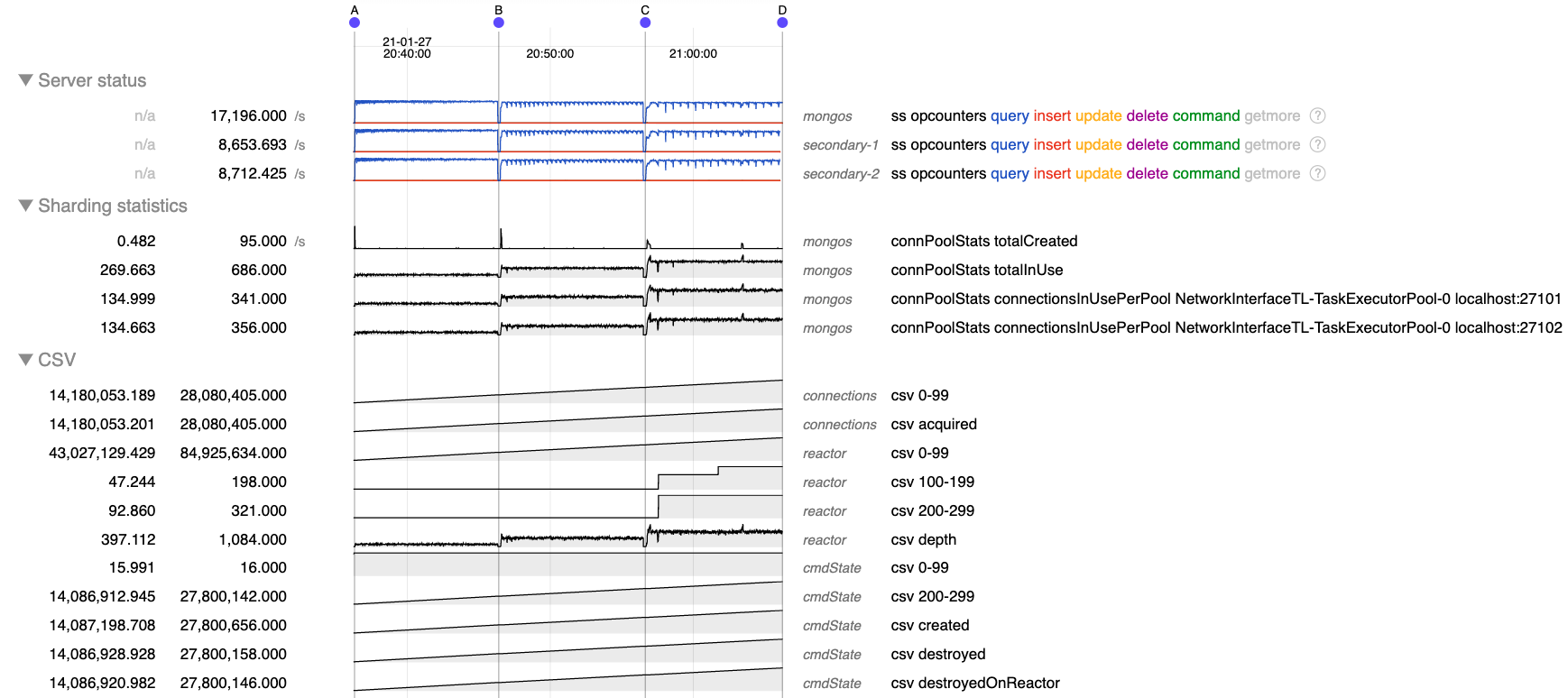

- is duplicated by
-
-
- Closed
-
- related to
-
SERVER-54278 Add feature flag to disable Opportunistic Reads by default
-
- Closed
-