-
Type:
Bug
-
Resolution: Incomplete
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: 4.4.9
-
Component/s: None
-
ALL
-
None
-
3
-
None
-
None
-
None
-
None
-
None
-
None
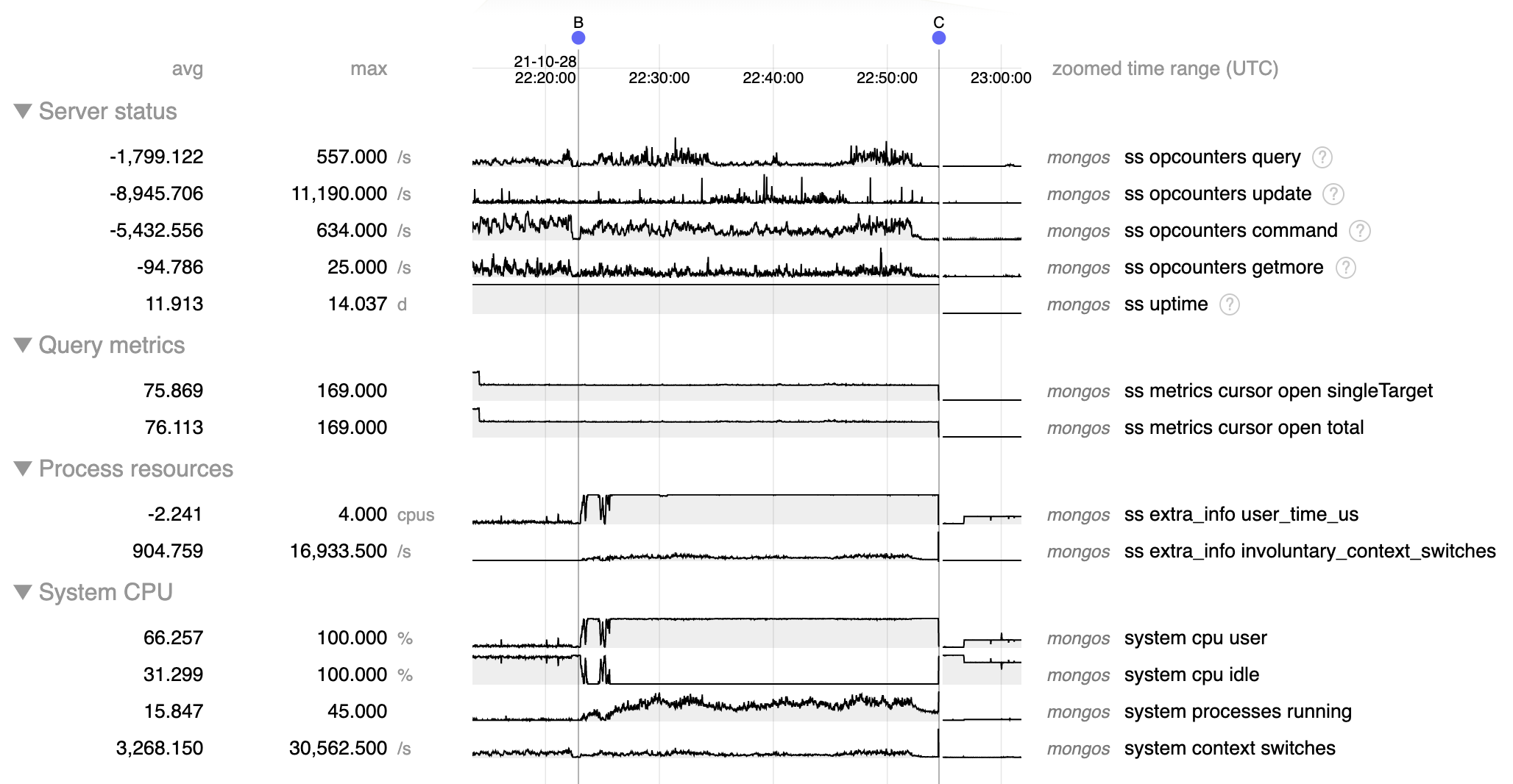
We have a big cluster (>7TB data), hosting a sharded collection. The collection was created as sharded, but the cluster initially only had 1 shard (call it shard A), and 3 mongos.
Today we added shard B. We disabled the balancer, added the shard in the cluster, defined 2 zones that fully covered the key space, then enabled the balancer.
The zones were defined in a way such that only few chunks should have been migrated to shard B (as an initial test).
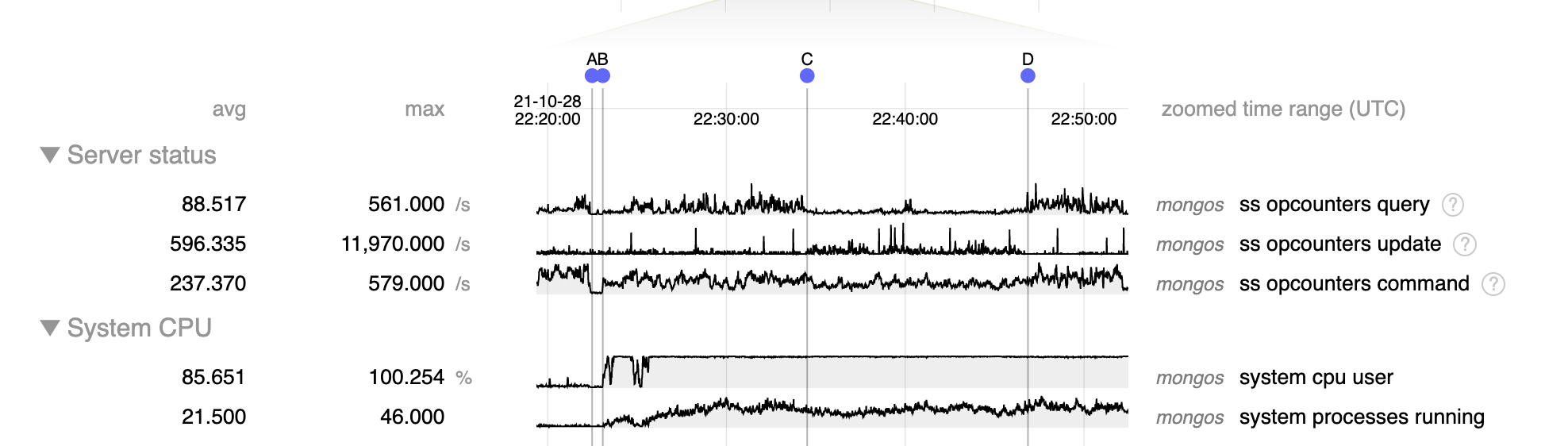
From the moment the balancer was enabled, CPU on the 3 mongos spiked to 200% (100% on both CPUs), causing major disruption to the incoming traffic. The balancer slowly moved chunks from shard A to shard B, at speed of a few seconds per chunk.
We thought the balancing operation was being the issue. So we disabled the balancer, but nothing changed.
Then we also completely stopped the workers that were performing queries to the cluster but that had no effect: mongos were still at 200% CPU.
We redefined the zones so that all chunks should have been migrated back to shard A and re-enabled the balancer, because we thought the presence of data on multiple shards was the culprit. This made no difference. Even when all chunks were migrated back to shard A, CPU on mongos was still at 200%.
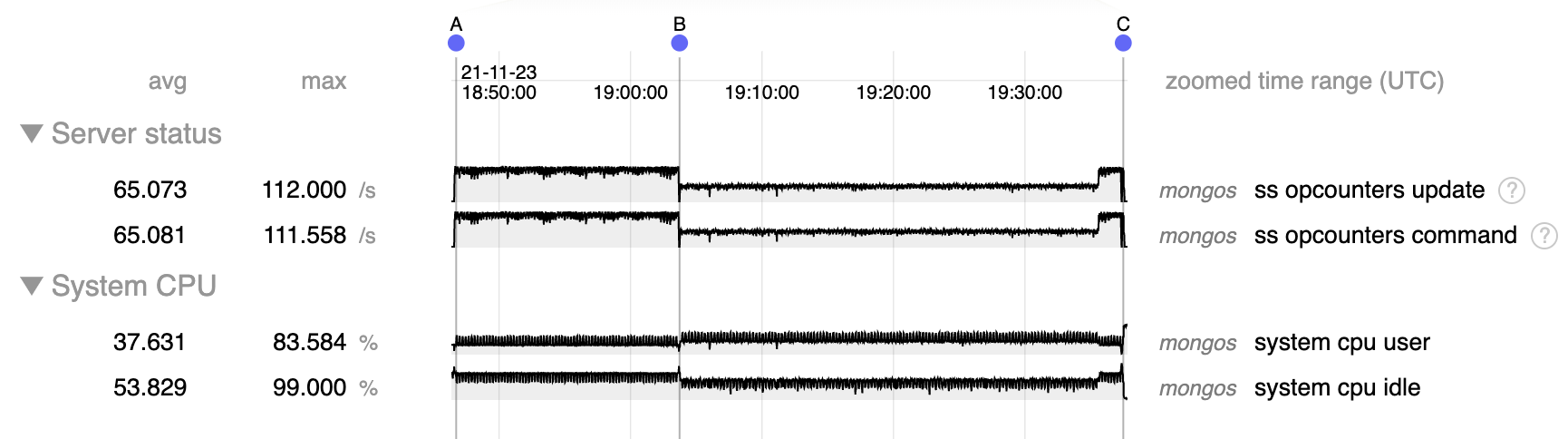
At this point we restarted the mongos, and CPU went back to 0. After that we could restart serving traffic normally from the mongos, with only shard A.
This procedure was repeated twice, with the same results. The second time it was performed on an upgraded cluster where machines had 4 CPUS.
I'm attaching some logs taken on a mongos when CPU was at 400% and no traffic was incoming. I took a sample of current ops on the machine, a mongostat report, and a few lines of mongos.log.