-
Type:
Improvement
-
Resolution: Fixed
-
Priority:
 Major - P3
Major - P3
-
Affects Version/s: None
-
Component/s: Replication, Write Ops
-
None
-
Storage Execution
-
Fully Compatible
-
v7.2, v7.0, v6.0, v5.0, v4.4
-
Execution Team 2023-03-06, Execution Team 2023-03-20
-
(copied to CRM)
-
None
-
None
-
None
-
None
-
None
-
None
-
None
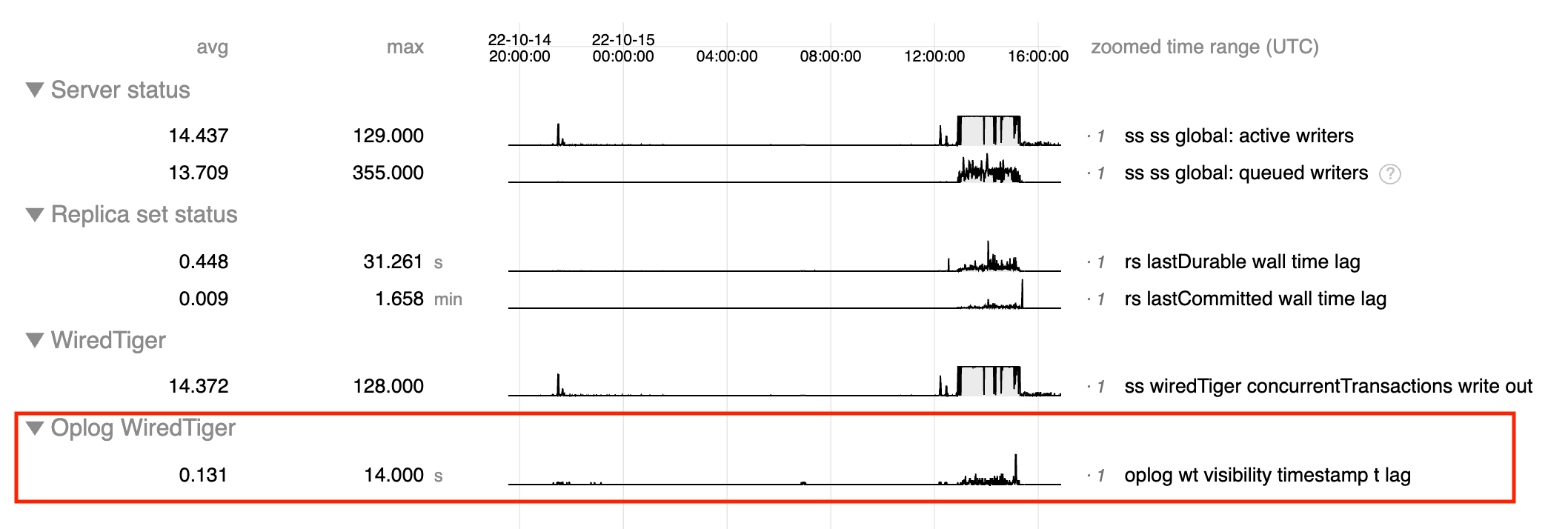
An oplog hole represents a Timestamp in the oplog an active storage transaction would commit at that is behind the Timestamp in the oplog an already-committed storage transaction wrote their oplog entry at. For example, it is possible for a storage transaction at Timestamp 20 to have committed and for a storage transaction at Timestamp 10 to commit later on in wall-clock time. Oplog readers are prevented from reading beyond the oplog hole to ensure they don't miss any oplog entries which might still commit. Keeping an oplog hole open for any extended period of wall-clock time can lead to stalls in replication.
Vectored insert is an example of an operation which pre-allocates Timestamps to write user data and the corresponding oplog entries at. In MongoDB 4.4, SERVER-46161 caused the default internal batch size for vectored insert to increase from 64 to 500. This has been seen to lead to higher tail latencies for vectored inserts (SERVER-65054).
Other operations cause oplog holes too. If expensive work is done (e.g. within an OpObserver) after the oplog slot is allocated and prior to the storage transaction committing, then those operations can stall replication too. Introducing some logging to track the time spent would give more insight into these areas and perhaps even be useful to signal on within our performance testing.

- is related to
-
SERVER-84449 High WiredTiger session concurrency can increase replication write latency
-
- Open
-
-
-
- Open
-
-
-
- Backlog
-
-
-
- Closed
-