As an end-user, I want to use the mongo-spark-connector 10.1.0 to write to the mongo collection.
Issue: While the json collection is being read and is written to MongoDB collection it is changing the default datatype of the schema taken into account when reading the JSON data.
As for the issue, it is converting the "string" to "int32" and "long" to "int64", which is causing issues in further aggregation or while reading the record from the collection.
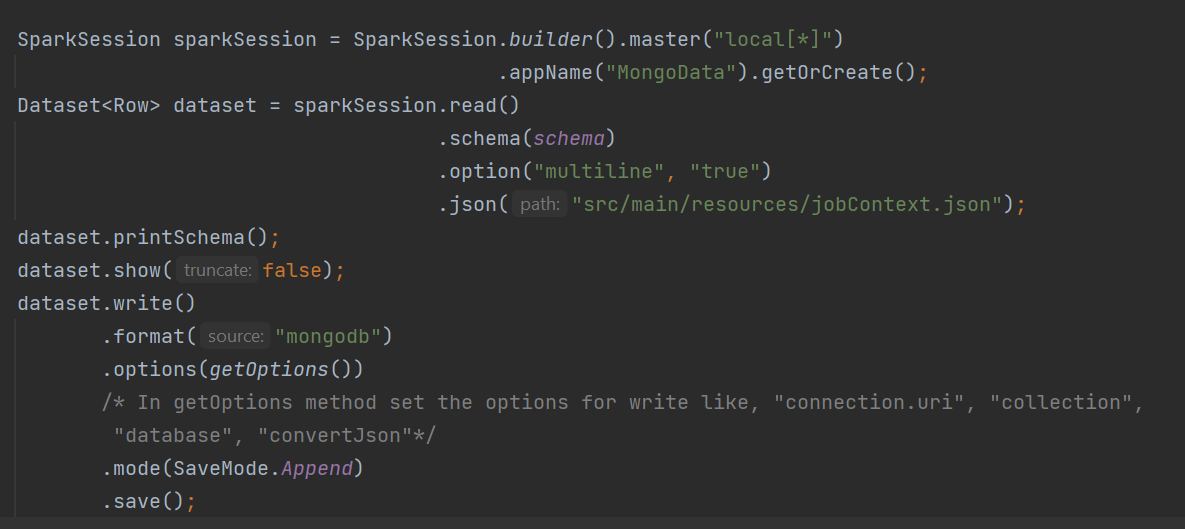
How to reproduce: code snippet
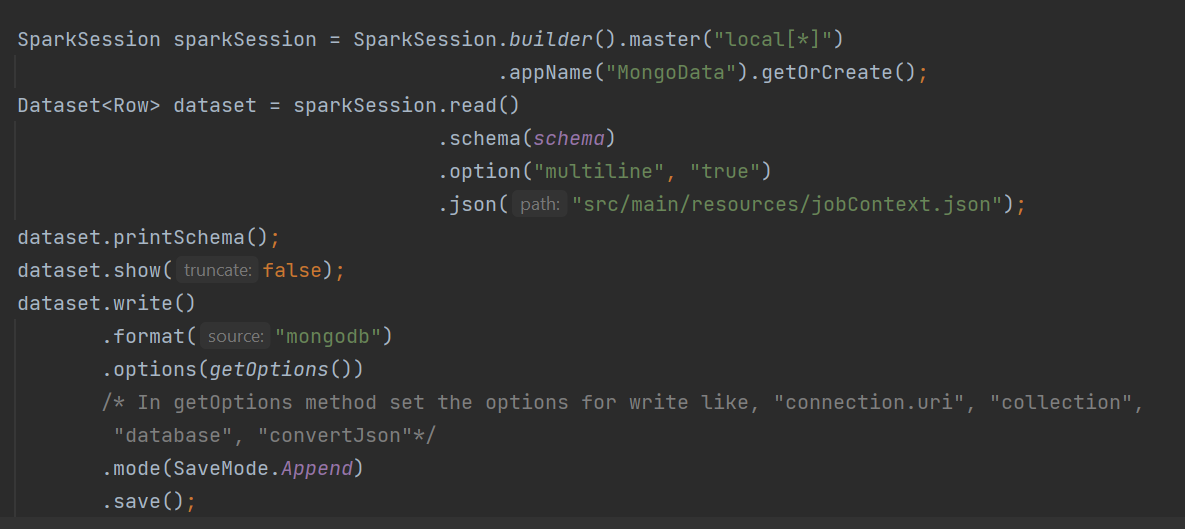
Expectation:
The change of datatype should not happen while writing to the mongo collection.
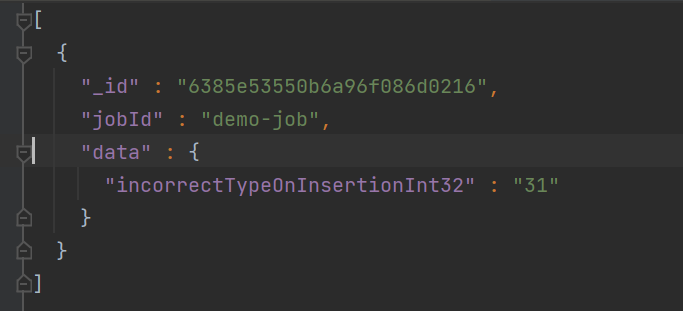
- is caused by
-
SPARK-311 Support BsonTypes that aren't natively supported in Spark
-

- Closed
-