-
Type:
Task
-
Resolution: Done
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: None
-
Component/s: Documentation
-
None
-
None
-
None
-
None
-
None
-
None
-
None
I have a sharded cluster consisting of 6 Nodes:
- 3 Replica Sets (rs0, rs1, rs2)
- 3 Config Servers
- 3 Mongos
- Each Replica Set consists of two Shardsvr (one primary, one secondary) and an Arbiter
When I use the MongoSpark Connector to connect to my cluster, I use these settings to connect to the Mongos.
val conf = new SparkConf() .setAppName("Cluster Application") .set("spark.mongodb.input.uri", "mongodb://hadoopb24:27017,hadoopb30:27017,hadoopb36:27017/test.data") .set("spark.mongodb.output.uri", "mongodb://hadoopb24:27017/test.myCollection")
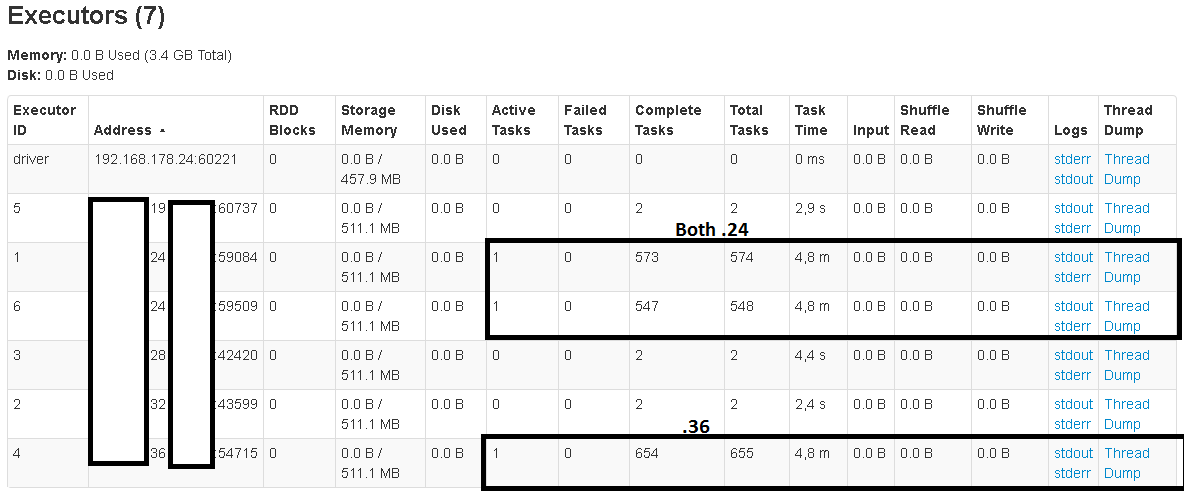
I launch 6 executors to parallelize the operations. However just two executors doing all the work:
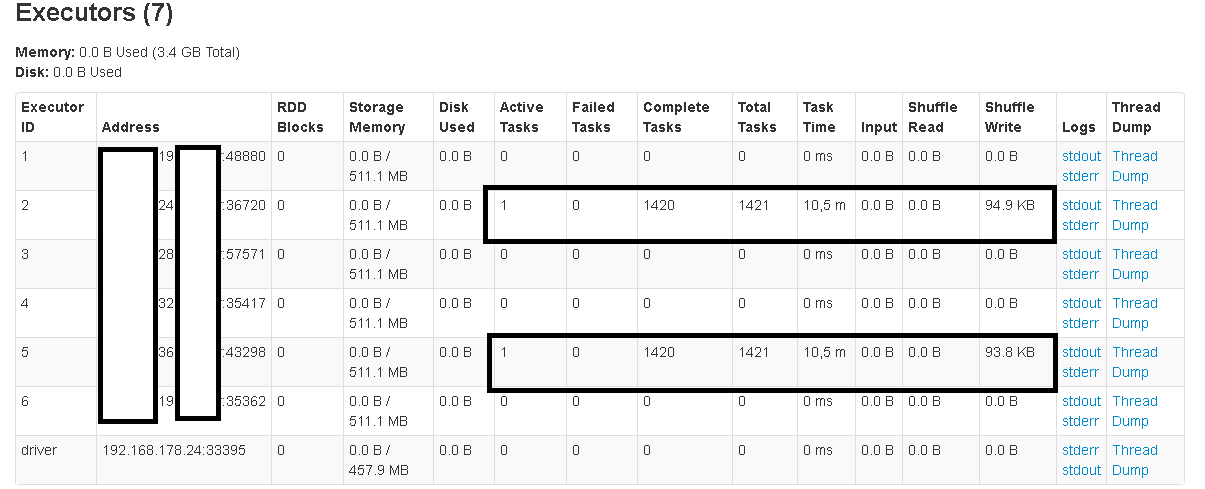
I also tried changing the readPreference.name value setting to "nearest", which should read from both primaries and secondaries. But it barely helps:
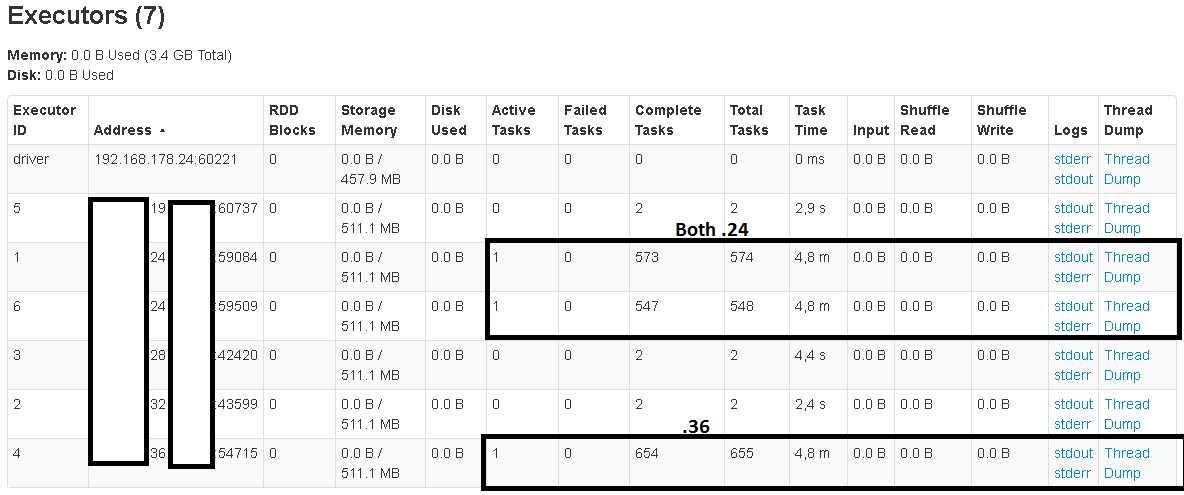
Each Replica Set holds some of the data that gets returned. The question: Do I have to connect to each of the Shardsvr instances rather than the Mongos? I expected that the mongos would lead to the best results. How can I achieve better parallelism?
The documentation could take a few words on this matter. I think my problem is related to this.