-
Type:
Bug
-
Resolution: Duplicate
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: 5.0.13
-
Component/s: Not Applicable
-
None
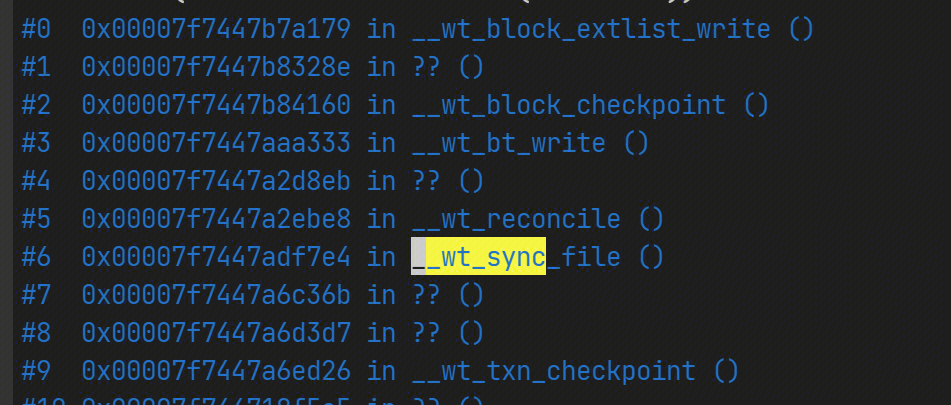
I found that one of our mongod nodes stored 2T of data, its freeStorageSize was 120G, and a large number of slow queries occurred at a certain moment during the checkpoint.
By printing the stack, I found that these user requests were stuck in obtaining the hazard pointer, and the checkpoint thread was making changes to the allocated available and discarded lists.
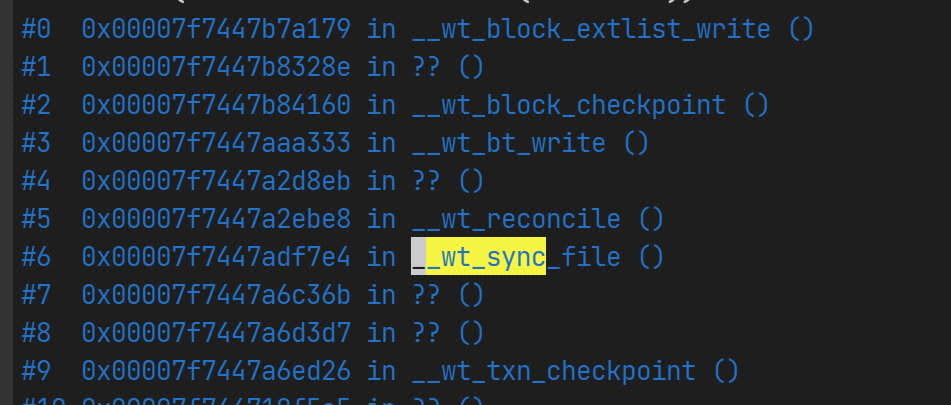

So I decided to rebuild the mongod node. The freeStorageSize of the new node was reduced to 10G, and these slow queries disappeared.
I suspect that freeStorageSize is too large, which makes the available list structure more complex, so checkpoint takes a particularly long time to process.
Live_lock has been held for a long time.
Therefore, the evict thread is stuck on the live_lock lock, and the page status is WT_REF_LOCKED, the corresponding request is waiting to get a hazard pointer of the page __wt_page_in_func.
May I ask if my suspicion is correct?
When processing the available list during checkpoint, is it necessary to be mutually exclusive with evict?

- is depended on by
-
WT-12903 If the freeStorageSize is too large, a large number of slow queries will occur during checkpoint
-
- Closed
-