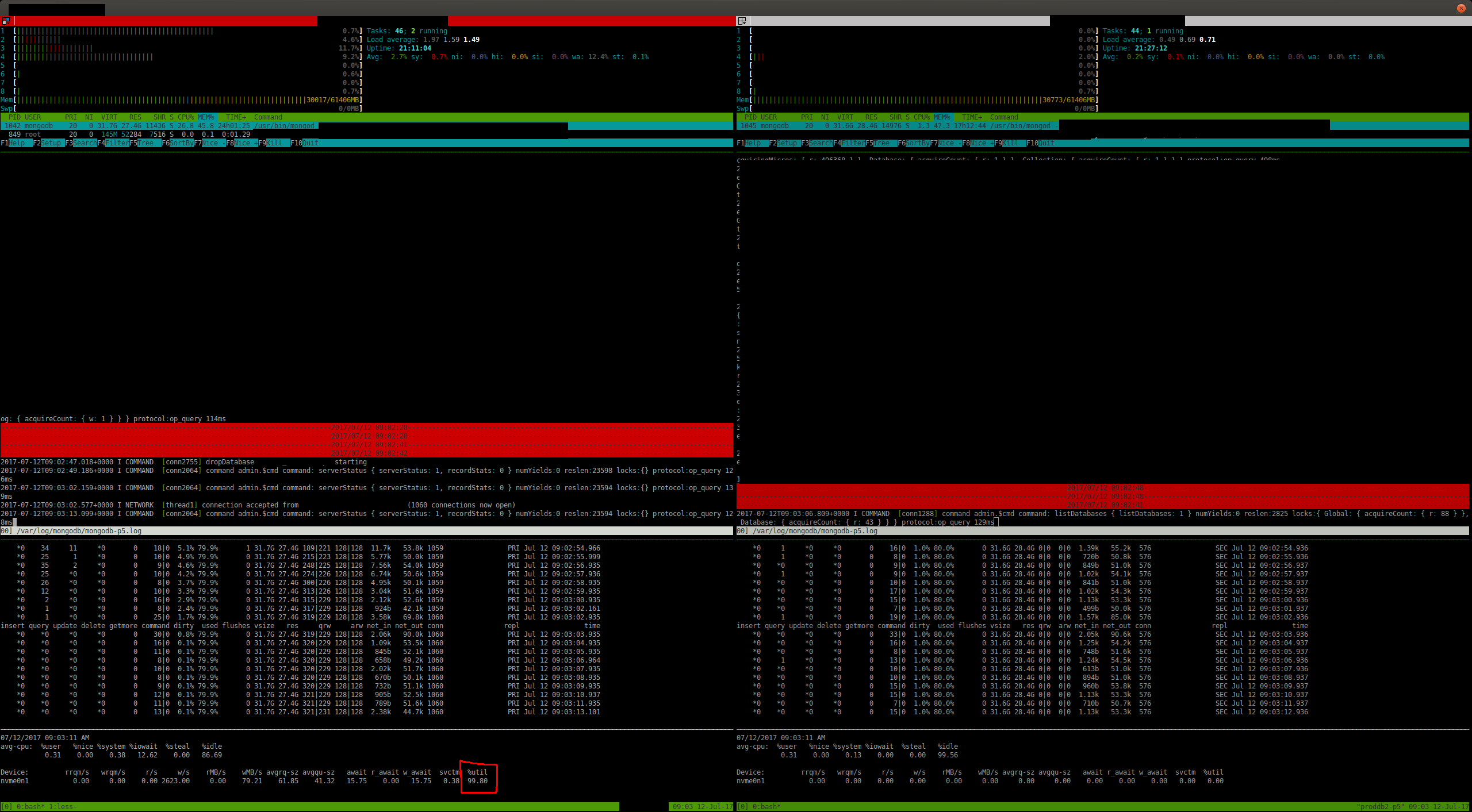
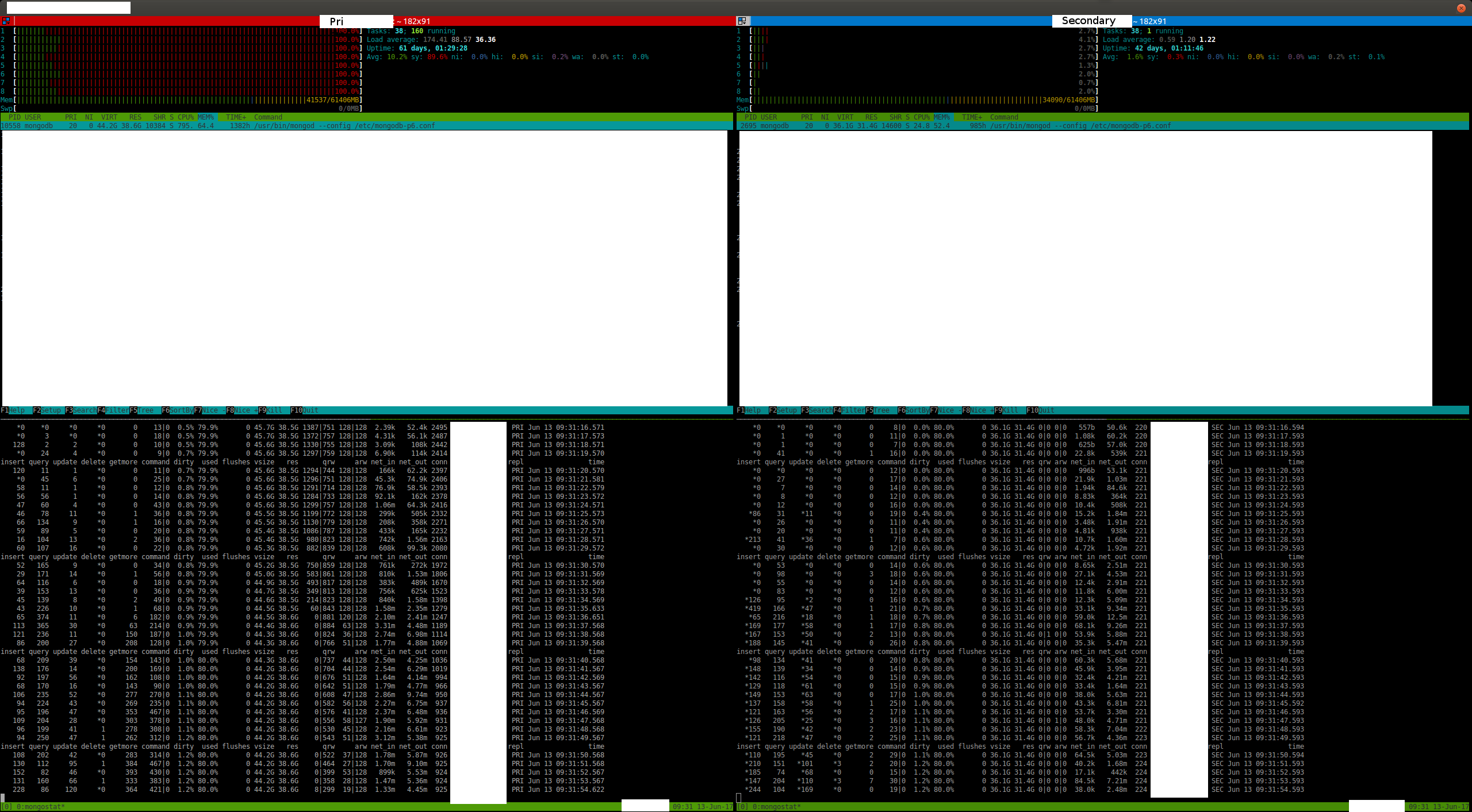
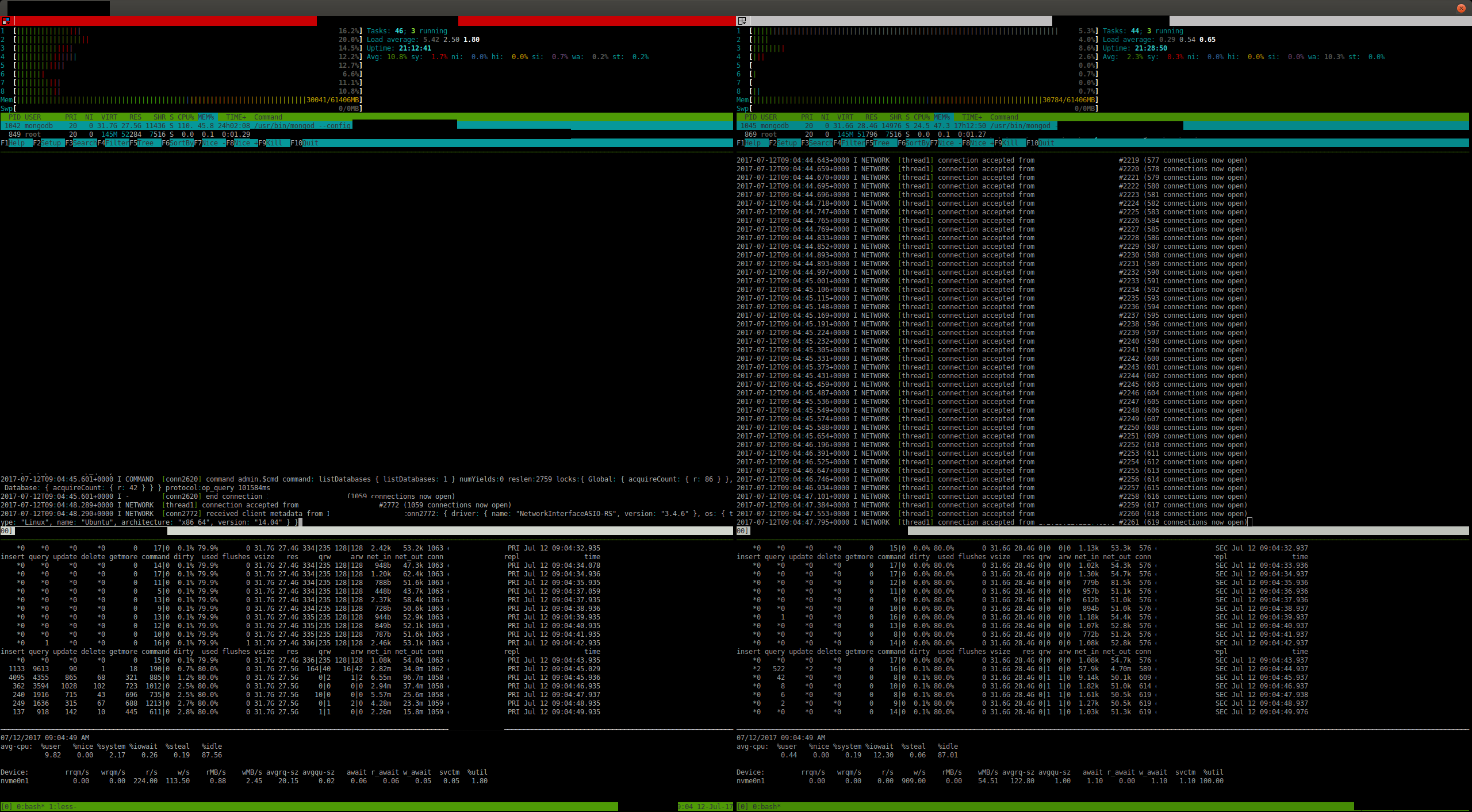
MongoDB customers have reported occasional slow operations when collection drops are executed concurrently with a checkpoint. MongoDB drop operations hold an exclusive database lock, so anything that causes a drop to be slow can block other operations.
There is machinery in the WiredTiger storage engine API implementation to deal with drops that cannot complete immediately. WiredTiger returns EBUSY and the storage engine implementation keeps a list of tables and will retry the drops later. This relies on a checkpoint_wait=false configuration to WT_SESSION::drop, which is intended to make the drop fail immediately instead of blocking due to a checkpoint.
However, if a table is clean at the start of a checkpoint then dropping it during the checkpoint with checkpoint_wait=false will block. The drop will spin on the special lock handle checkpoint is holding rather than failing immediately. The drop thread is holding the table lock at that point, blocking new cursors from being opened.
My preferred solution here is to move the handle gathering stage of checkpoints until after scrubbing, and after it has started its transaction because then it can safely skip clean handles. That is non-trivial because metadata-changing operations can complete after the transaction starts but before handles are locked (e.g., creates, bulk load completion).
- is duplicated by
-
SERVER-29419 Dropping unused indexes adversely affects query performance
-

- Closed
-
-
-

- Closed
-
- links to