-
Type:
Bug
-
Resolution: Unresolved
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: None
-
Component/s: None
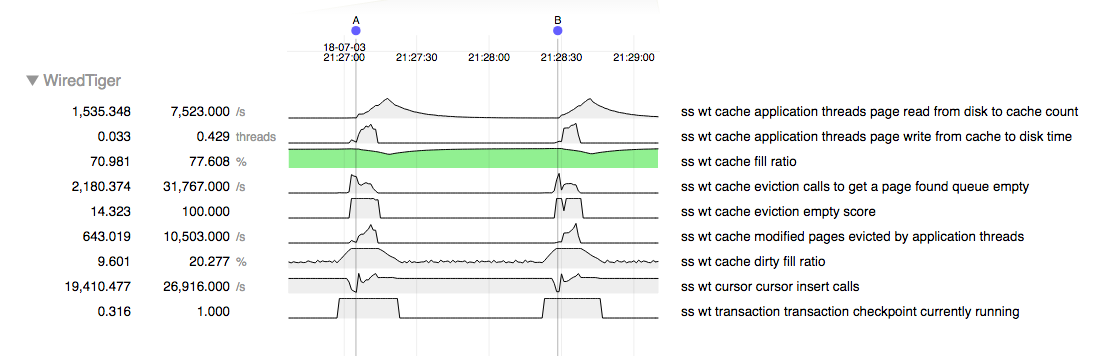
The following wtperf configuration simulates a workload on 18000 tables, pushing the dirty cache above 20% during checkpoints. A brief slowdown of several seconds is observed that can be explored for possible improvements.
# wtperf configuration to use lots of tables, and look for stalls related to eviction and checkpoints. conn_config="cache_size=10GB,eviction=(threads_min=4,threads_max=4),log=(enabled=false),checkpoint_sync=false,checkpoint=(wait=60),statistics=[all],statistics_log=(wait=1,json),file_manager=(close_idle_time=100000),session_max=50000" table_config="leaf_page_max=32k,internal_page_max=16k,allocation_size=4k,split_pct=90,type=file" table_count=18000 log_like_table=true icount=50000000 # Avoid flushing the handle cache between ops. reopen_connection=false populate_threads=1 random_range=50000000 report_interval=1 run_time=600 # Have lots of threads do relatively few operations, so stalls are unexpected but there # is enough throughput to generate cache pressure. threads=((count=100,updates=1,throttle=200),(count=100,reads=1,throttle=200)) value_sz=100
{kind=link}