-
Type:
Bug
-
Resolution: Works as Designed
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: None
-
Component/s: None
-
None
-
8
-
Storage - Ra 2020-10-19, Storage - Ra 2020-11-02, Storage - Ra 2020-11-16
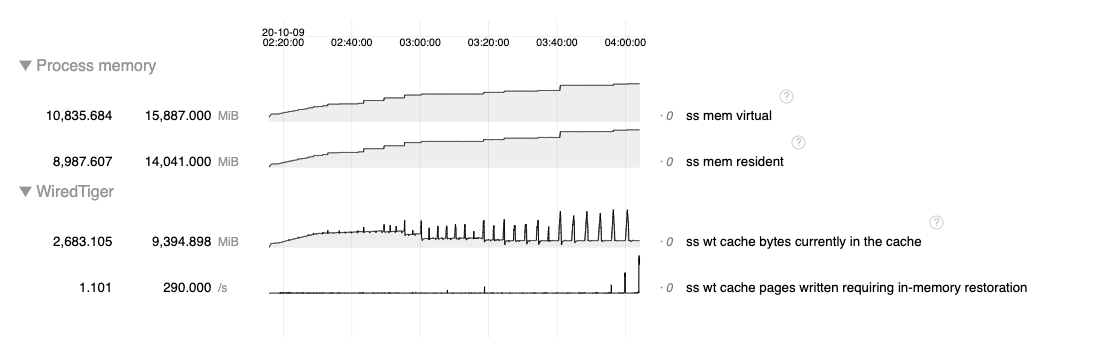
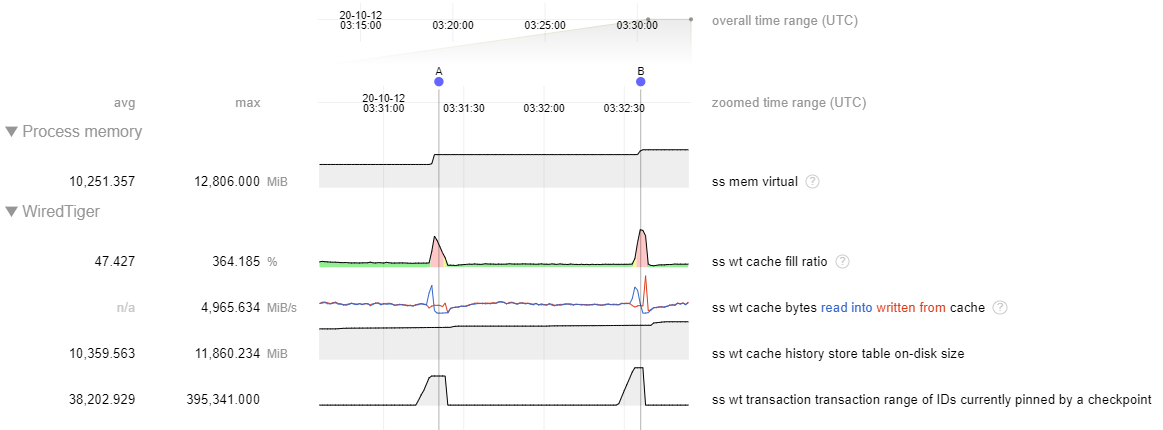
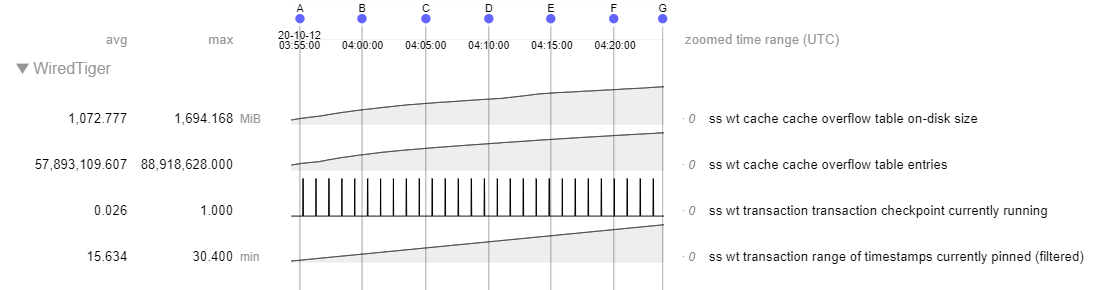
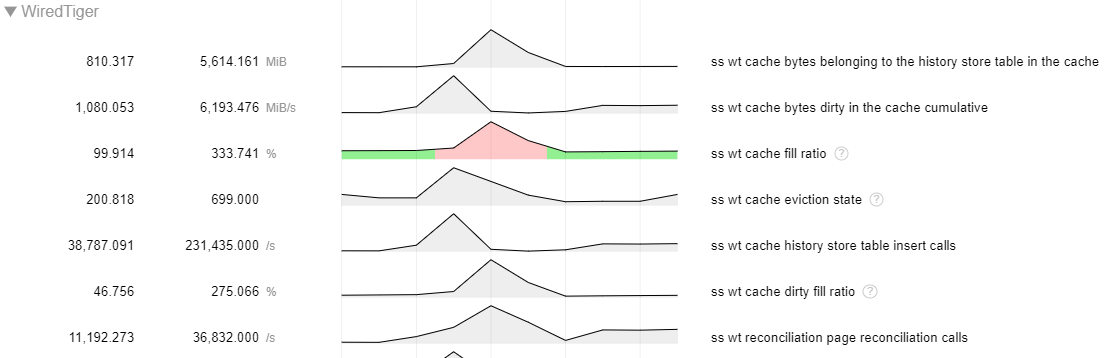
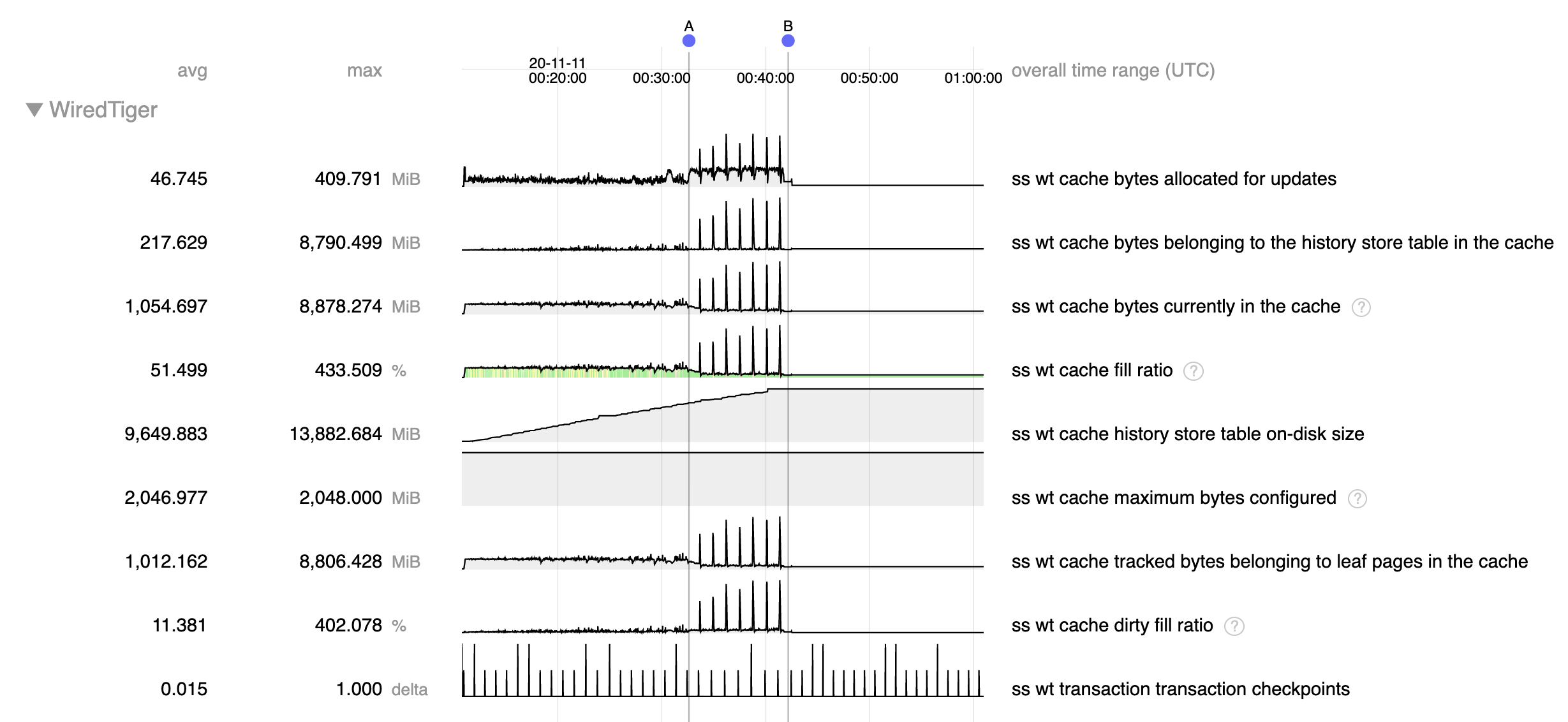
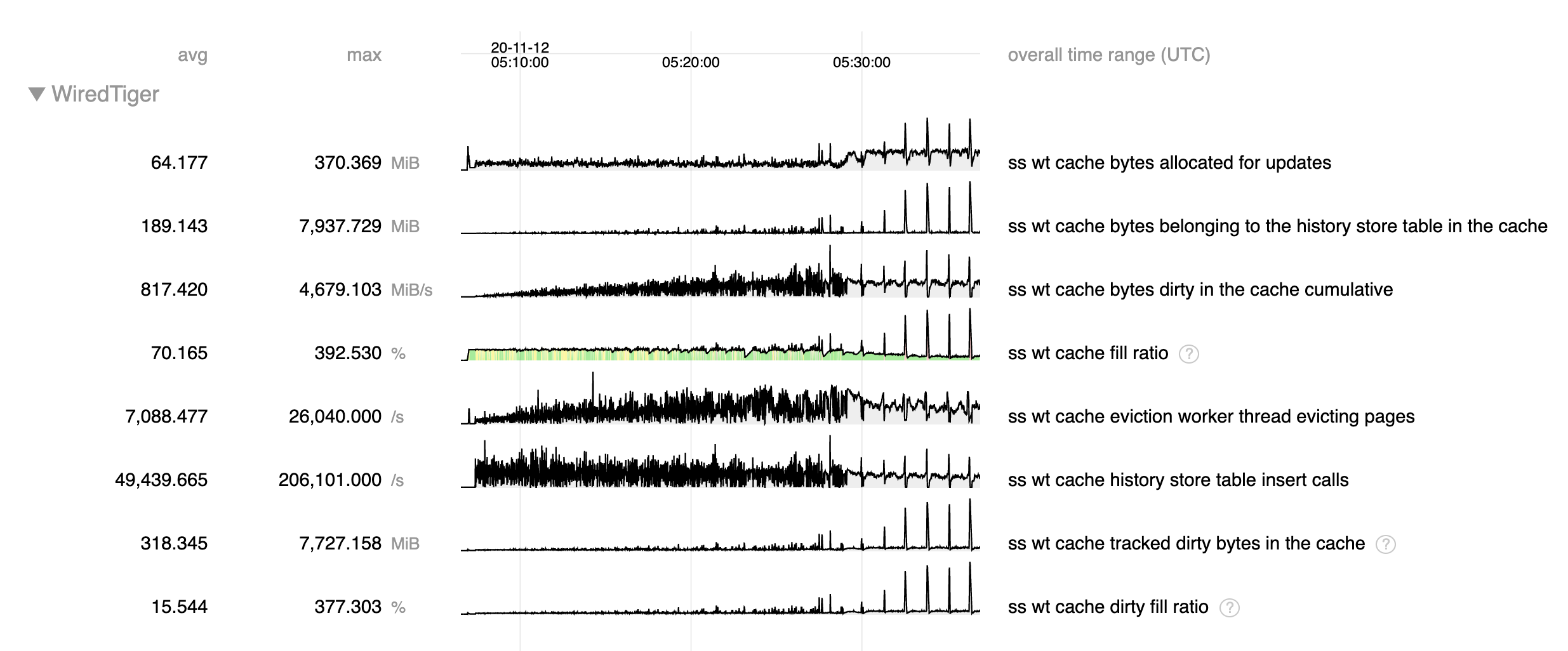
In a recent support ticket, bruce.lucas found a scenario with a replica set member down where we see rapid growth in the history store compared with the lookaside file in 4.2 (~2.5 GB vs ~15 GB). For full context, read the description and comments in the linked ticket.
Symptoms
When observing statistics, we noticed:
- Stalling during checkpoint.
- Cache usage spiking during checkpoint.
- History store file taking up lots more disk space.
As of this moment, I think that the large history store file can explain the other two symptoms so we're more interested in diagnosing that. Lots of history store pages will mean that it can dominate the cache and since the history store file is last in line to get checkpointed, those pages will be pinned to the cache during checkpoint leading to high cache usage and stalling due to application threads being tasked with eviction.
Ideas
Time windows are making the difference
In the repro, we are creating a record with a 100-byte string and two integers and modifying the two integers repeatedly. From a WiredTiger point of view, this is going to look like lots of tiny modify updates.
One theory is that since the records are small and we're storing a time window for each one in the history store, this cell metadata may dominate the disk usage. I added some logging in the cell packing code and found that about 4.5 GB of uncompressed unpacked integers were being written to cells which doesn't seem to be enough to account for the difference in disk usage.
Evicted pages between checkpoints are contributing to disk usage
When pages are evicted in between checkpoints, their disk image is added to the data file meaning they can exist twice. Since lookaside wasn't checkpointed, this can't happen. In the absolute worst case (which can't happen with our write pattern), we could get a 2x increase which is still not enough.
Checkpoints are being kept around unnecessarily
I added some logging to print the number of checkpoints in the system in __ckpt_process but I only ever saw 0-1 printed which seems to indicate that this is not the case. Also, I am seeing blocks constantly being freed which shouldn't be the case if we're keeping checkpoints around like this.
This one still seems suspicious but I haven't seen much evidence to confirm it.
Repro
You'll probably have to change some paths depending on where your mongo repo is in order to get this working.
repro.sh
server=localhost
uri="mongodb://$server:27017/test?replicaSet=r"
db=/home/alexc/work/mongo/db/
eMRCf="--enableMajorityReadConcern true"
opts="--setParameter enableFlowControl=false --wiredTigerCacheSizeGB 2 $eMRCf"
function js {
echo xxx js $1
./build/install/bin/mongo $uri --eval "load('repro.js'); $1"
}
function setup {
killall -9 -w mongo mongod mongos
rm -rf $db
mkdir -p $db/{r0,r1,r2}
./build/install/bin/mongod --dbpath $db/r0 --port 27017 --logpath $db/r0.log --replSet r --fork $opts
./build/install/bin/mongod --dbpath $db/r1 --port 27117 --logpath $db/r1.log --replSet r --fork $opts
./build/install/bin/mongod --dbpath $db/r2 --port 27217 --logpath $db/r2.log --replSet r --fork $opts
./build/install/bin/mongo --eval 'rs.initiate({_id: "r", members: [
{
"_id" : 0,
"host" : "127.0.0.1:27017"
},
{
"_id" : 1,
"host" : "127.0.0.1:27117"
},
{
"_id" : 2,
"host" : "127.0.0.1:27217",
"arbiterOnly" : true
}
]})'
sleep 5
js 'setup()'
}
function update {
function monitor {
echo "time,size"
cd $db
while true; do
printf '%s,%s\n' $(date +%s) $(du -s . | cut -f 1)
sleep 1 >/dev/null
done
}
pkill -f monitor
monitor >$db/size.csv &
pkill -f r1.log
while pgrep -f r1.log; do sleep 1; done
sleep 2
js 'update()'
}
setup
update
repro.js
load("/home/alexc/work/mongo/jstests/libs/parallelTester.js")
const nthreads = 20
function setup() {
db.c.createIndex({t: 1})
const threads = []
for (var t=0; t<nthreads; t++) {
thread = new Thread(function(t) {
const size = 500
const count = 100*1000;
const every = 100
const doc = {a: -1, x: 'x'.repeat(size), b: -1, t: t}
many = new Array(every).fill(doc)
for (var i=0; i<count; i+=every) {
db.c.insertMany(many)
if (i%10000==0) print(t, i)
}
}, t)
threads.push(thread)
thread.start()
}
for (var t = 0; t < nthreads; t++)
threads[t].join()
}
function update() {
const threads = []
for (var t=0; t<nthreads; t++) {
thread = new Thread(function(t) {
var start = new Date()
for (var i=0; ; i++) {
db.c.updateMany({t: t}, {$set: {a: i, b: i}})
print(t, i)
if (new Date() - start > 30*60*1000)
break
}
}, t)
threads.push(thread)
thread.start()
}
for (var t = 0; t < nthreads; t++)
threads[t].join()
}





- related to
-
-
- Closed
-