-
Type:
Improvement
-
Resolution: Unresolved
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: None
-
Component/s: None
-
None
-
None
Summary
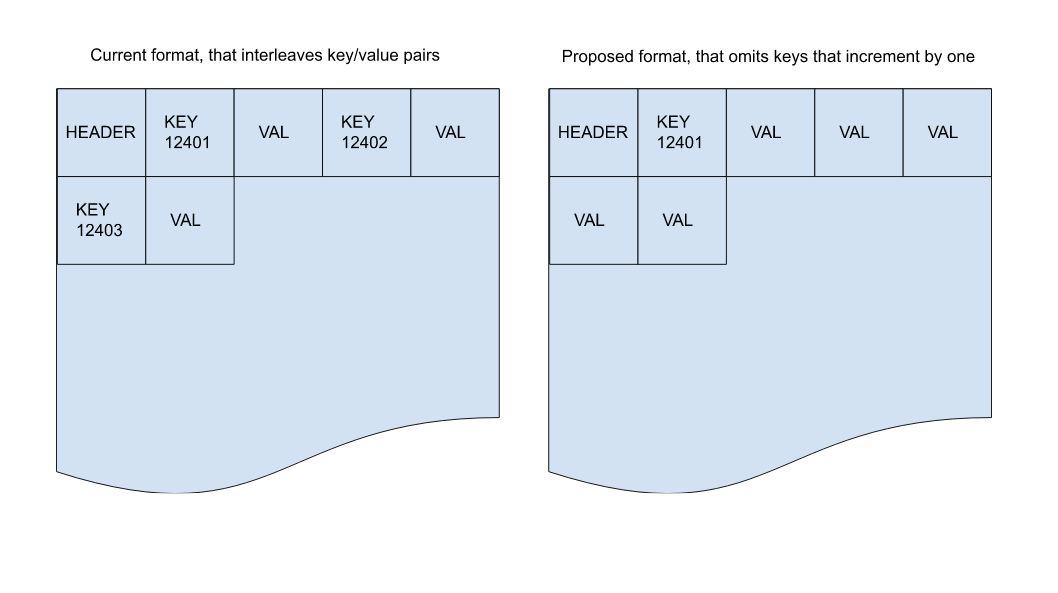
WT should have a special key cell encoding to cover the case where two adjacent keys are identical except that the last byte has been incremented by 1.
Motivation
- Does this affect any team outside of WT?
This will have the biggest impact on columnar indexes because it has the combination of frequently having adjacent keys matching this pattern, combined with frequently storing very small values (0-5 bytes will be very common in cases we care about), so that every byte of overhead is significant.
This also occurs in the RecordStore (key_format=q), although a) the values tend to be much larger, so the overhead is lower, and b) we aren't using prefix compression there, which might be a gate for this encoding.
- How likely is it that this use case or problem will occur?
Extremely common for columnar indexes. Within a column, the only case where keys won't match this is if there are gaps in record id space caused by deletes or rolled-back inserts.
- If the problem does occur, what are the consequences and how severe are="q" they?
If I understand correctly, the smallest storage a key can consume with WT_CELL_KEY_SHORT_PFX is 3 bytes. For a one-byte value that means a total of 5 bytes for that kv-pair (including the WT_CELL_VALUE_SHORT byte). If the incrementing of the key could be encoded implicitly by having adjacent values, then that could be as low as 2 bytes for that pair, for a 60% savings. Or looking at it another way, we have 150% of unnecessary overhead today.
Even if this doesn't shrink the total index size significantly, it can significantly shrink the size of some columns, which will accelerate queries that use them. Since numeric columns with "reasonable" numbers will be some of the most commonly used queries, and those values will have very compact representations, this will have an oversized perf impact that won't necessarily show up in the index size.
- Is this issue urgent?
It isn't urgent, but it would be nice to have prior to columnar GA (which is currently targetting for 6.3). If we get it prior to columnar GA, then we have less upgrade/downgrade concerns since we can just assume that all columnar indexes have this ability. We can evaluate whether we want to enable it for other WT tables in mongo separately, but for columnar we have a "clean slate" until GA.
Acceptance Criteria (Definition of Done)
When will this ticket be considered done? What is the acceptance criteria for this ticket to be closed?
- Testing
What all testing needs to be done as part of this ticket? Unit? Functional? Performance?Testing at MongoDB side?
- Documentation update
Does this ticket require a change in the architecture guide? If yes, please create a corresponding doc ticket.
[Optional] Suggested Solution
I think the best option is to let two adjacent value cells without an intermediate key imply that the prior key gets its last byte incremented by 1. This means that for a page with all incrementing keys, you only need to store the first key, then all remaining data is just values with no overhead.
One question is how to detect this. The simplest would be to check if the common prefix for two keys is everything except for the last byte, then subtract the bytes and see if the result is 1. This would let you use the optimized layout for 255 out of every 256 keys, with the final key needing 3 bytes when you overflow the last byte. A more comprehensive check would involve subtracting the first differing byte (wherever it is) and then checking if the remaining bytes in the old and new key are 0xFF and 0x00 respectively (and they are the same size). This case is also an increment by one, but with carry.
Whichever detection you choose to use, I suggest adding the carry logic in the detector to loop if adding 1 to the last byte results in 0. This should have almost no overhead (at least on x86), but will ensure that if we ever try to detect increment with carry on the encoder side, it isn't a breaking change for the decoder, so we don't have backwards compatability concerns.